CC BY 4.0 (除特别声明或转载文章外)
在我们学习编程语言时,往往都是从打印 “hello world” 开始,因此往往我们接触到的第一个库函数就是打印函数,如 C 语言的 printf 函数;C++ 的 std::cout 等等,但就是这样一个看似简单的打印函数却蕴含这巨大的乾坤,我们可以以此为起点一直深入探究,从函数的传参、函数调用、汇编指令、CPU的指令执行甚至是电信号的变换,这一张知识网撒下去将变得巨大无比。当然本文不试图探索这整个知识网,非不为也,而不能也(自身知识储备不足)。
本文将从我一个普通的程序员视角出发,以 printf 为引子,从而引发出来的一系列知识点的探究与思考,考虑的自身水平能力有限,某些部分可能不全面或者存在错误,如有错误,欢迎批评指正,那么,开始发车了。
CPU 是如何执行一条指令的
我们知道高级语言最终都会被“翻译”成机器指令,以便能被 CPU 识别并执行,这些指令会统一放在一个叫“代码段”的地方,当可执行程序运行后,CPU 会串行的从主存中(通常指内存)取出这些指令依次执行,这个过程可以抽象成:取指(instruction fetch) ➡️ 译码(instruction decode) ➡️ 执行(instruction execute) 循环。
为了能更透彻的理解这个指令周期,我们必须对 CPU 的内部构成有一个大概的了解,CPU 可以简单分为控制器和运算器两个部分,它们的作用分别如下:
- 运算器,负责对数据进行加工,它里面还可以细分更多的元件。
- ALU(
arithmetic and logic unit算数逻辑单元),负责算术运算(加减乘除等)和逻辑运算(位移、大小比较等)。 - 通用寄存器组,如AX、BX、CX、DX、SP等,用于存放操作数(包括源操作数、目的操作数和中间结果)和各种地址信息等。
- 累加器(
accumulator),用来储存计算产生的中间结果,专门存放算术或逻辑运算的一个操作数和运算结果的寄存器,能进行加、减、读出、移位、循环移位和求补等操作。它属于暂存寄存器,IR 和 PC 也属于暂存寄存器。 - 程序状态寄存器(
Program Status Word),保留有算术逻辑指令或测试指令的结果而建立的各种状态信息,包括OF、SF、ZF、CF等,其中的位参与并决定微操作的形成。
- ALU(
- 控制器,负责控制整个CPU 的工作,是一个指挥枢纽。同样它也由很多元件组成。
- PC(
Program Counter),程序计数器,属于暂存寄存器,里面存放的是 CPU 将要执行的下一条指令的地址。 - IR(
Instruction Pointer),指令寄存器,也属于暂存寄存器,保存当前正在执行的指令。 - ID(
Instruction Decoder),译码器,翻译指令比特串,分析指令的操作码,以决定指令的操作性质和方法,然后向操作控制器发出具体的控制信号,完成所需功能。 - MAR(
Memory Address Register),存储地址寄存器,既用来保存CPU将要取的指令/数据的内存地址,又保存CPU将要写入数据的内存地址。 - MBR(
Memory Buffer Register),存储数据寄存器,也可以简写为 MDR(Memory Data Register),存放向主存写入的信息或从主存中读出的信息。 - CU(
Control unit),控制单元,控制 CPU 中指令和数据的传输,协调 CPU 的各个部分,例如通过控制总线向内存发送读/写信号。
- PC(
下图描述了 CPU 执行 mov 指令的一个大概流程。

指令执行流程
接下来我们按照上图来梳理下 CPU 执行 mov 0x8(%ebp),%edx 这条指令的具体流程,这条指令的作用是将 ebp+8 所指向地址的 4 字节数据赋值到 edx 寄存器中。
- ① PC 寄存器内存储的地址传递给 MAR 寄存器;
- ② MAR 通过地址总线寻址,同时控制单元 CU 向内存发送读信号;
- ③ 内存把寻址后得到的数据通过数据总线发送到 MBR 寄存器;
- ④ MBR 把数据再传递给 IR 指令寄存器;
- ⑤ IR 再将指令比特数据传给 ID 进行译码;
- ⑥ ID 进行译码,获得指令的 opcode 以及操作数信息;
- ⑦ 把算出来的操作数内存地址再次传递给 MAR;
- ⑧ 同步骤②,CPU 向内存寻址取数据;
- ⑨ 同步骤③,内存数据传递到 MBR;
- ⑩ 最终把栈内存上的数据送到寄存器中;
可以结合下面这张动图(取自网络,侵删)来理解执行的执行流程。
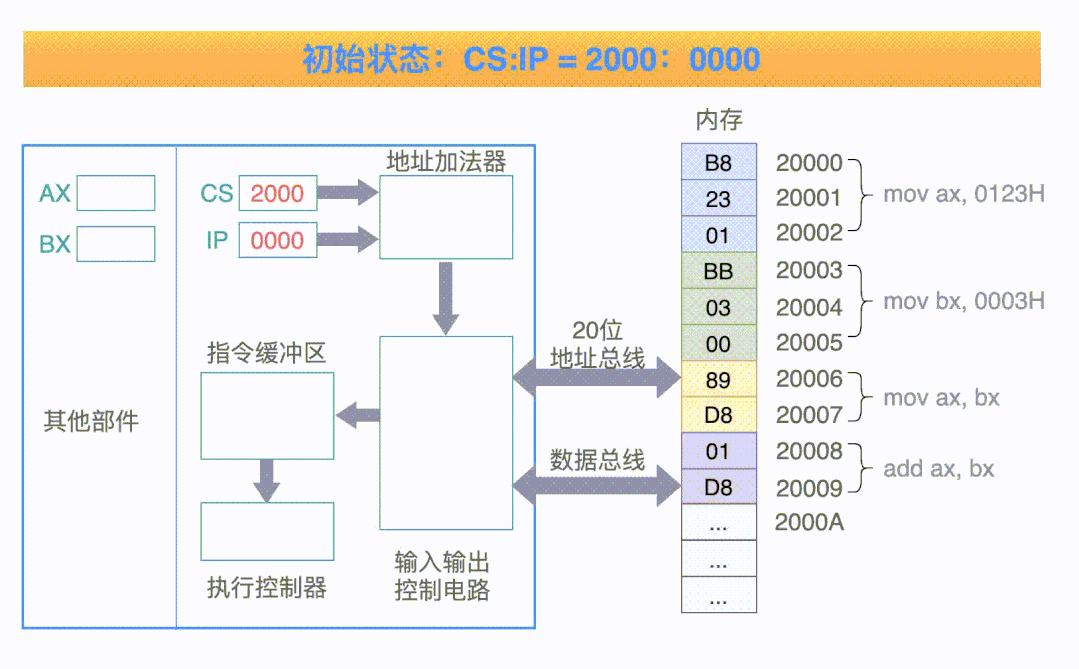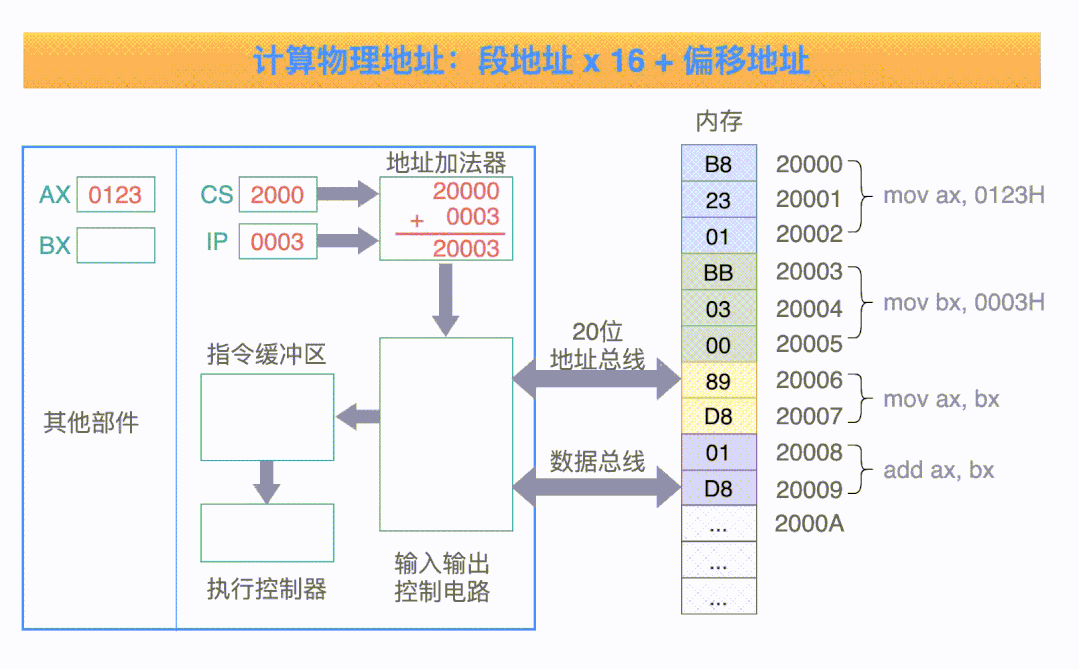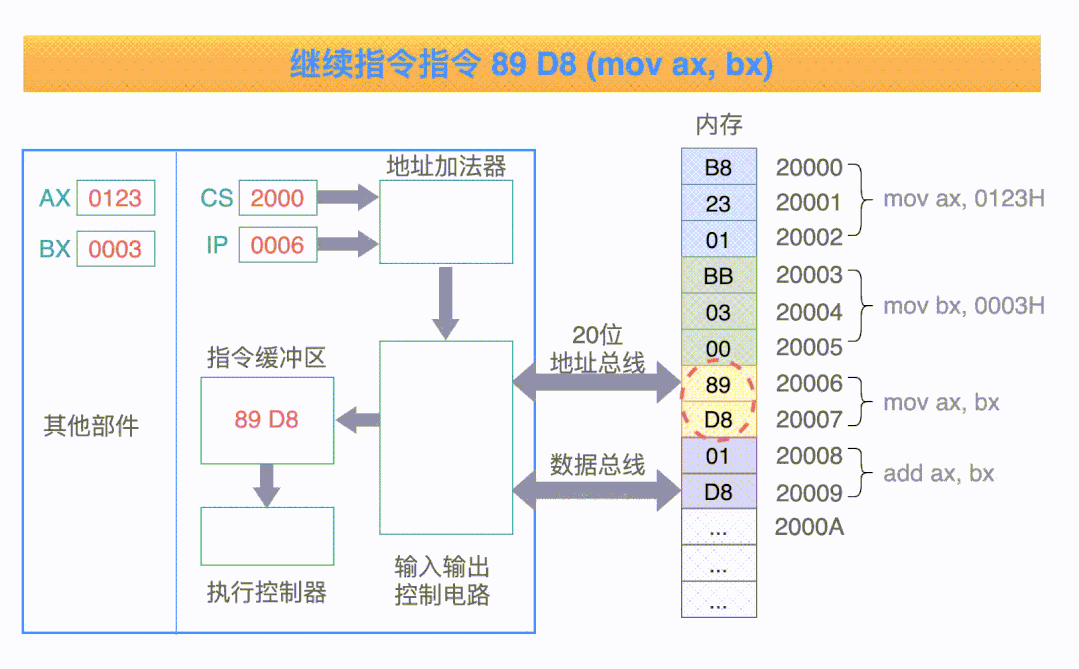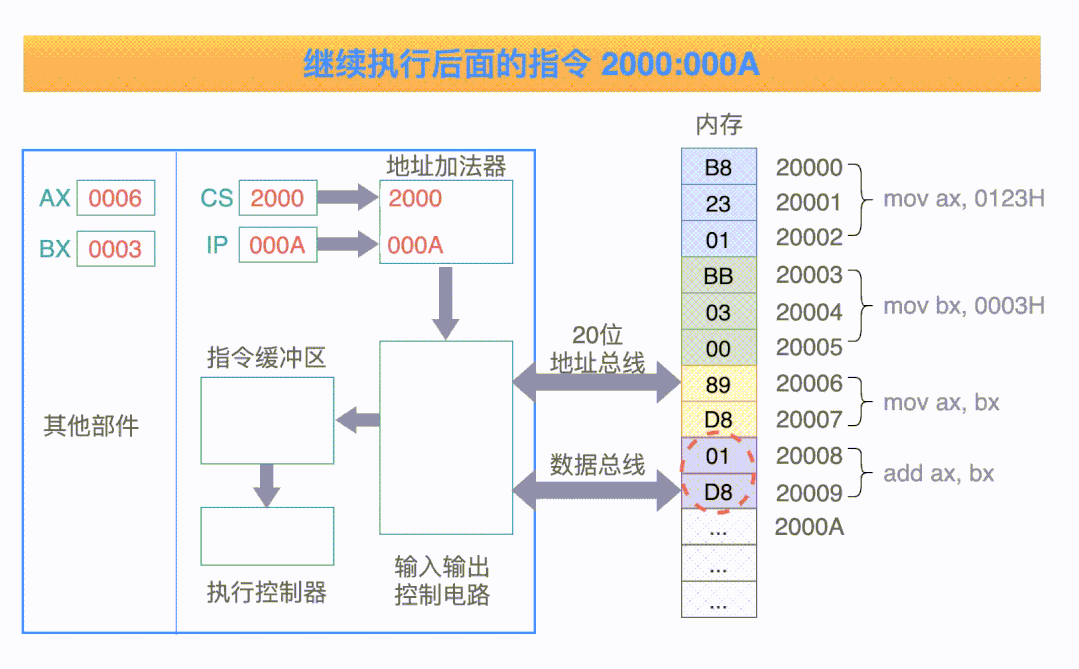
以上,关于 CPU 的内部结构就有了一个粗糙浅显的轮廓了。当然,现代的 CPU 内部已经非常复杂了,例如多核心多级缓存等等,但是我们普通人的学习目的是了解 CPU 的基本框架,不必太过深入。
取指
CPU 通过 PC 寄存器(Program Counter Register,在 x86 下为 IP 寄存器Instruction Pointer) 就能知道要获取的指令所在的内存地址(线性地址),通过地址总线(Address Bus)和控制总线(Control Lines)去内存中寻址被找到存放在内存中的指令,然后指令通过数据总线(Data Bus)送到 CPU 的 IR 寄存器(Instruction Register)。
译码
CPU 取到指令都是一串比特串,这一串比特到底代表是什么意思就需要译码器了。指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法,更细节一点说,通过查看指令的操作码(opcode)就知道在指令集架构(Instruction Set Architecture)内该指令是做什么运算的,而操作码后面的比特数据可以提供操作数相关信息,例如指令是否需要操作数、操作数是否是一个立即数或是一个寻址值:寄存器或存储器地址等。大多数指令 CPU 只要看指令的第一个字节就可以知道具体指令的形式了。
秉承“实践出真知”的理念,接下来我们汇编一个简单的代码,来学习 i386 的指令格式以及隐藏在其中的细节,从而对译码过程有一个更具体的理解。示例代码如下:
// i386.c
int sum(int a, int b) {
int i = 100;
int c = a + b;
return c;
}
int main(void) {
int a = 67;
int b = 21;
sum(a, b);
return 0;
}
为了减少干扰,我们这里不包含任何诸如 stdio.h 之类的头文件,使用 gcc 进行编译,因为我使用的是 x86_64 系统,为了编译 32 位程序,需要指定 -m32 参数,编译命令如下:
gcc -m32 i386.c -o i386
若编译报错,则需要运行 sudo apt-get install libc6-dev-i386 gcc-multilib 安装相关依赖库。编译完后使用 objdump -d ./i386 反汇编,抠出 main 和 sum 两个函数的汇编指令。
0000118d <sum>:
118d: 55 push %ebp
118e: 89 e5 mov %esp,%ebp
1190: 83 ec 10 sub $0x10,%esp
1193: e8 4f 00 00 00 call 11e7 <__x86.get_pc_thunk.ax>
1198: 05 44 2e 00 00 add $0x2e44,%eax
119d: c7 45 f8 64 00 00 00 movl $0x64,-0x8(%ebp)
11a4: 8b 55 08 mov 0x8(%ebp),%edx
11a7: 8b 45 0c mov 0xc(%ebp),%eax
11aa: 01 d0 add %edx,%eax
11ac: 89 45 fc mov %eax,-0x4(%ebp)
11af: 8b 45 fc mov -0x4(%ebp),%eax
11b2: c9 leave
11b3: c3 ret
000011b4 <main>:
11b4: 55 push %ebp
11b5: 89 e5 mov %esp,%ebp
11b7: 83 ec 10 sub $0x10,%esp
11ba: e8 28 00 00 00 call 11e7 <__x86.get_pc_thunk.ax>
11bf: 05 1d 2e 00 00 add $0x2e1d,%eax
11c4: c7 45 f8 43 00 00 00 movl $0x43,-0x8(%ebp)
11cb: c7 45 fc 15 00 00 00 movl $0x15,-0x4(%ebp)
11d2: ff 75 fc push -0x4(%ebp)
11d5: ff 75 f8 push -0x8(%ebp)
11d8: e8 b0 ff ff ff call 118d <sum>
11dd: 83 c4 08 add $0x8,%esp
11e0: b8 00 00 00 00 mov $0x0,%eax
11e5: c9 leave
11e6: c3 ret
我们就以 sum 函数中的 mov 0x8(%ebp),%edx 这条指令为例,这条指令的作用是把 0x8(%ebp) 这个内存地址所指向的值赋值到 %edx 寄存器中,其中 0x8(%ebp)所指向的内存里存放的是 main 函数中的局部变量 b 通过压栈传参给 sum 函数的实参 b,其值为 21。这条指令所对应的二进制数据为 8b 55 08,长度为三个字节,如果不了解 i386 指令集,这三个字节鬼看得懂,so,接下来会简单描述下 i386 指令格式,让我们“教会” CPU 认识这三个字节。
i386 指令格式
通过查阅 i386 指令手册,它的指令格式结构如下:
+-----------+-----------+-----------+--------+------+------+------+------------+-----------+
|instruction| address- | operand- |segment |opcode|ModR/M| SIB |displacement| immediate |
| prefix |size prefix|size prefix|override| | | | | |
|-----------+-----------+-----------+--------+------+------+------+------------+-----------|
| 0 OR 1 | 0 OR 1 | 0 OR 1 | 0 OR 1 |1 OR 2|0 OR 1|0 OR 1| 0,1,2 OR 4 |0,1,2 OR 4 |
| - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -|
| number of bytes |
+------------------------------------------------------------------------------------------+
可以把上面的结构分割成两个部分:指令前缀和指令。
- 指令前缀,可选的,每个指令前缀占1个字节,最多4字节,即最多可以按任意顺序指定4种不同的指令前缀。
+---------------+---------------+---------------+---------------+
| INSTRUCTION | ADDRESS- | OPERAND- | SEGMENT |
| PREFIX | SIZE PREFIX | SIZE PREFIX | OVERRIDE |
|---------------+---------------+---------------+---------------|
| 0 OR 1 0 OR 1 0 OR 1 0 OR 1 |
|- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -|
| NUMBER OF BYTES |
+---------------------------------------------------------------+
- 指令,包括操作码、寻址格式(
ModR/M和SIB)、位移量和立即数
+----------+-----------+-------+------------------+-------------+
| OPCODE | MODR/M | SIB | DISPLACEMENT | IMMEDIATE |
| | | | | |
|----------+-----------+-------+------------------+-------------|
| 1 OR 2 0 OR 1 0 OR 1 0,1,2 OR 4 0,1,2 OR 4 |
|- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -|
| NUMBER OF BYTES |
+---------------------------------------------------------------+
为了简单起见,我们这里不讨论指令前缀,而是着重于指令部分。指令由操作码(opcode)和操作数(operand) 组成,操作码是必须的,占用1到2个字节,上面也说过,大部分指令都是1字节的,这种指令 CPU 识别起来就很难简单,而多字节的指令可以通过转义码或者ModR/m字节的 opcode 域来扩充;操作数则可能没有,例如一些无操作数的指令 leave、ret 等,操作数又可以分为可寻址值和立即数。
接下来我们对指令进行详细的拆解:
- opcode 决定了指令的基本形式,如是否有操作数、操作数的个数、操作的方向等。
- 通过 opcode 就能确定接下来的一个字节性质,若指令需要对操作数寻址,则接下来的这个字节为
ModR/M - 当存在
ModR/M字节时,又能确定接下来的字节是否是SIB字节 - 剩下的
DISPLACEMENT和IMMEDIATE则分别表示地址偏移量和立即数
寻址形式字节
寻址形式字节有 3 个域,分别为:Mod、opcode/reg、r/m,它的比特位结构如下:
7 6 5 4 3 2 1 0
+--------+-------------+-------------+
| MOD | REG/OPCODE | R/M |
+--------+-------------+-------------+
MOD域,占用高位的 2 个比特,它可以和R/M组合成 32 种索引模式,若 mod 为 3,也就是二进制 11 时,R/M表示是寄存器编号;不为 3 是,则R/M表示内存寻址;REG/OPCODE,占用接下来的 3 个比特,从它的书写格式就可以知道(有斜杠”/”)它既可以表示寄存器编号,也可以表示操作码信息,具体来说,即当指令的 opcode 第一个字节还不能确定具体的指令形式时,就会读取reg/opcode域作为 opcode的一部分, 最终才能决定具体的指令形式。R/M,占用最后的 3 个比特,可以指定寄存器的编号或者作为内存寻址模式编码的一部分;
上面所说的这三个域所组合成的索引模式可以在i386手册-指令格式中查到,本文不再赘述。
这里我们还是拿上面的 mov 0x8(%ebp),%edx 的二进制(8b 55 08)做一个演示。通过查询手册得到 opcode为 8B 指令表,会发现有两条,因为我们使用的 32 位地址寻址,所以对应下面的第二条。
Opcode Instruction Clocks Description
8B /r MOV r16,r/m16 2/4 Move r/m word to word register
8B /r MOV r32,r/m32 2/4 Move r/m dword to dword register
现在我知道了该 opcode 是将一个寄存器或者内存值移动到一个 32 位宽的寄存器,那么操作数就涉及到了寻址,因此 opcode 后面的一个字节就是 ModR/M,查询手册后得知ModR/M字节 3 个域的具体意义:
mod=(01),它确定了r/m域是一个内存地址,即第二个操作数需要从内存中获取;reg/opcode=(010),可以确实是寄存器编号而非 opcode 扩展,它在 32 位下对应的寄存器编号为 2,即 edx 寄存器;r/m=(101),确定了第二个操作数的寻址方式为disp8[ebp],即在 ebp 寄存器内存放的地址上偏移一个 8 bit 的立即数,也即是0x8(%ebp);
下图展示了该指令的具体形式:

SIB字节
32 位的寻址才需要这个字节,它紧跟在 ModR/M 字节之后,一般用于比例变址寻址。它也有 3 个域:SS(scale,比例因子)、index(索引寄存器编号)、base(基址寄存器编号)。它的比特位结构如下:
7 6 5 4 3 2 1 0
+--------+-------------+-------------+
| SS | INDEX | BASE |
+--------+-------------+-------------+
它的 3 个域的组合形式可以参考指令手册中的 Table 17-4。
寻址格式
这里顺便总结下 10 种不同的寻址方式:
| 寻址方式 | Intel 汇编格式 | AT&T 汇编 |
|---|---|---|
| 立即寻址 | mov eax, 1000h | mov $0x1000, %eax |
| 寄存器寻址 | mov eax, ebx | mov %ebx, %eax |
| 直接寻址 | mov eax, [1000h] | mov ($0x1000), %eax |
| 寄存器间接寻址 | mov eax, [ebx] | mov (%ebx), %eax |
| 寄存器相对寻址 | mov eax, 1000h[esi] | mov 0x1000(%esi), %eax |
| 基址变址寻址 | mov eax, [ebx][esi] | mov $0x1000, %eax |
| 相对基址变址寻址 | mov eax, 1000h[ebx][esi] | mov 0x1000(%ebx,%esi), %eax |
| 比例变址寻址 | mov eax, 1000H[esi*2] | mov 0x1000(,%esi,2), %eax |
| 基址比例变址寻址 | mov eax, [ebx][esi*4] | mov (%ebx,%esi,4), %eax |
| 相对基址比例变址寻址 | mov eax, 1000H[ebx][esi*8] | mov 0x1000(%ebx,%esi,8), %eax |
目前主流的汇编格式分为:intel汇编和AT&T汇编,前者作为 Windows 系统的汇编格式;后者作为 Linux 系统的汇编格式,下面的例子描述了两个汇编格式的差异:
- Intel 汇编
汇编指令:sub eax, [ebx + ecx * 4h - 20h] 计算方式:[<base register> + <index register> * <scale> + <offset>] - AT&T 汇编
汇编指令:subl -0x20(%ebx, %ecx, 0x4), %eax 计算方式:<offset>(<base register>, <index register>, <scale>)
另外,在 AT&T 格式中表示偏移量或者缩放因子时,立即数前面不需要加 $;在表示数值时则需要加 $,如mov $0x100,%eax。在 AT&T 汇编格式种,寻址的地址可统一成下面的格式,计算时,直接代入到下面的公式,没有的项填 0 即可。
地址或偏移(%基址或偏移量寄存器, %索引寄存器, 比例因子)
内存地址 = 地址或偏移 + %基址或偏移量寄存器 + %索引寄存器 * 比例因子
执行
在译码过,接着就进入执行阶段,运算器开始工作,进行算术运算或逻辑运算,例如 ALU 完成加法运算等。当然具体的运算工作肯定是极其复杂,这里不深入探讨,了解即可,在执行完指令之后会更新 PC (intel 上是 IP) 寄存器的值,接着进入下一个循环周期。
未完待续
- 函数调用过程,包括栈帧、参数传递,涉及到的指令有 push call leave ret,以及 IP 的变化
- 分段内存管理和分页内存管理
- 变长参数的实现,i386 和 x86_64 的实现区别