CC BY 4.0 (除特别声明或转载文章外)
定时器(timer)模块是整个 skynet 框架中最为简单、耦合度最低一个模块,但也是一个不可或缺的模块,游戏中有很多玩法功能都依赖于定时器,例如:在线时长礼包、玩家上的buff 和 debuff 等等。
在 skynet 中,使用了时间轮(time wheel)算法来实现定时器模块,定时器的逻辑由专门的线程(thread_timer)进行负责,节点中的服务向定时器注册定时消息,然后由 timer 线程每隔一段时间转动一次时间轮(在 skynet 中,每隔 10 ms 转动一次时间轮),由此触发该轮下的定时消息,并派发定时事件到对应的服务。
关于定时器的实现算法主要有两种:最小堆和时间轮。redis 使用了最小堆(我印象中早期是使用的最小堆,后面的版本没有关注);linux 内核使用了时间轮。
时间轮
时间轮算法的本质就是用有限的刻度实现时间的无限轮回,一次时间轮回的长度就是该时间轮能表达的最大时长。其实现方式就是模拟了我们生活中的手表(机械手表),只不过手表把时、分、秒三个轮盘合并成了一个轮盘,而把刻度指针分为了三个。
现在,我们把手表的轮盘按照时、分、秒拆分成三个,它们的轮盘刻度分为为:12(时)、60(分)、60(秒),因此手表的时间轮模型一共有 12 + 60 + 60 = 132 个刻度,走完一整轮的时长为 12 * 60 * 60 = 43200 秒。
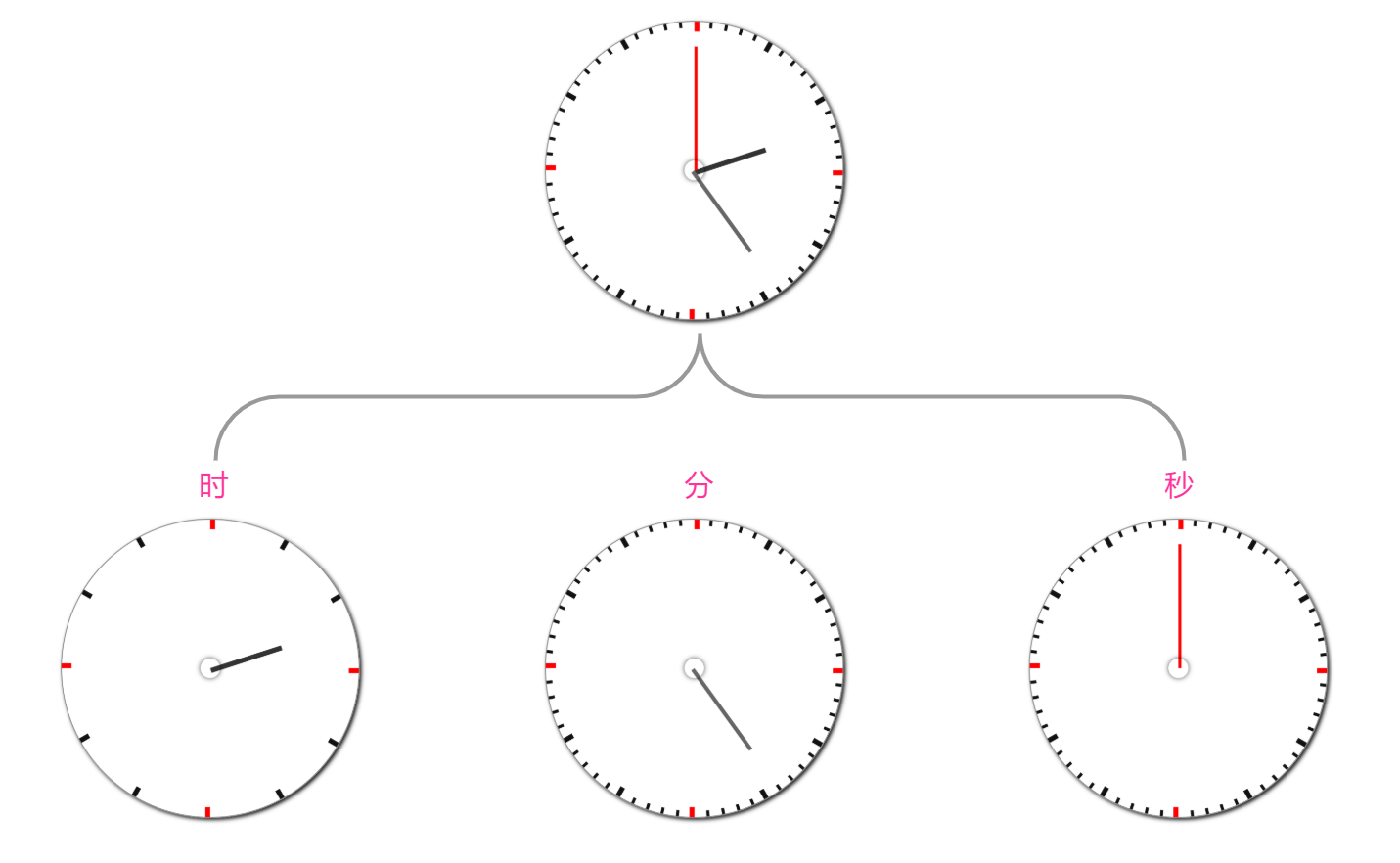
像手表这样的时间轮模型分了时、分、秒三层的,属于分层时间轮,每一层的轮回时间都是逐层递增,例如:走完一整圈『秒轮』,需要 60 秒;再提升一层,走完一圈『分轮』就需要 60*60 秒;再往上一层就需要 12*60*60 秒,也就是上面所说的这个手表的时间轮最大轮回时长。
那为什么需要时间轮呢?
首先,我们假设要编写这样一个程序:每隔 1 秒打印一个数字,一直打印 12 小时(43200 秒),且这些数字预先就确定并排好了顺序,例如第 1 秒打印数字 100,第 2 秒打印数字 200 … 那该怎么设计这个定时器呢?一个最简单粗暴的方式是创建一个容量为 43200 的数组,并把要打印的对应数字填入到数组中,然后以 1 秒为间隔,循环这个数组。
虽然上面的实现方式可以满足需求,且时间复杂度为 O(1),但是存在两个问题:
- 定时器数组占用的连续内存空间会随着最大定时时长的增大而增大,若需要这个定时程序运行 365 天,数组的长度就是
86400 * 365,假如一个数字用 4byte 来表示,就需要 120+ Mb 的连续内存空间,这种方式显然是不可取的; - 根据上一条的问题,这种方式不能实现无线循环的定时器,因为我们的连续内存空间是有限的;
注意,为什么这里一直在强调是连续内存空间,是因为不管采用数组或是链表的方式,最终用于存储定时数字的内存总空间并不会减少,只不过为了能快速索引到对应的时间轮刻度,使用的数组的方式来存储数据,而为了实现定时器,耗费大块的连续内存空间是不划算的;而如果采用链表的方式,又会导致链表查询耗时增加。
而时间轮模型就很好的解决了上面的问题,它的核心思想是:把最近一轮要到期的定时事件放到最外的轮盘(我称之为“工作轮盘”)中,且定时器只会从最外的轮盘中触发定时消息;若最外层轮盘走完一轮后,则向上一层的轮盘(我称之为“发散轮盘”)取出一批定时数据;若上一层轮盘也走完一轮后,则向上上轮取一批,以此类推。
为了彻底弄懂时间轮的工作流程,我们来看一个生活中的例子:每一年绝大部分的中国人都会经历春运,我们历经千辛万苦抢到一张高铁票,只等春节放假开开心心、安安全全回家。等到了回家那天,我们提早到达了高铁站, 接下来从到达车站到进入候车室会经过下面几个步骤:入站、验票、安检。现在假设高铁站的最大容量有 3000 人(站内 1000 + 站外广场 2000),且只有一个安检机,车站工作人员为了快速有序的安检,采用了时间轮模型对乘客进行了排队分组,大概的模型如下:

车站排队模型
从上图可以得知,不同层级的分组容量是不一样的,层级越高分组容量越大,例如广场上一组的容量为 1000人,验票通道每个分组的容量为 100 人,且它们存在如下关系:广场分组容量(1000) = 验票分组容量(100) x 验票分组个数(10)。现在对车站的 3000 个乘客进行编号并排队分组,他们的初始分布情况如下:
安检通道(工作轮盘):1-10 号
安检排队(第一层发散轮盘):
- 排队分组1 :虚空分组(已发散到安检通道)
- 排队分组2 :11-20 号
- 排队分组3 :21-30 号
- 排队分组4 :31-40 号
- 排队分组5 :41-50 号
- 排队分组6 :51-60 号
- 排队分组7 :61-70 号
- 排队分组8 :71-80 号
- 排队分组9 :81-90 号
- 排队分组10:91-100 号
验票排队(第二层发散轮盘):
- 排队分组1 :虚空分组(已发散到安检排队)
- 排队分组2 :101-200 号
- 排队分组3 :201-300 号
- 排队分组4 :301-400 号
- 排队分组5 :401-500 号
- 排队分组6 :501-600 号
- 排队分组7 :601-700 号
- 排队分组8 :701-800 号
- 排队分组9 :801-900 号
- 排队分组10:901-1000 号
进站排队(第三层发散轮盘):
- 排队分组1 :虚空分组(已发散到验票排队)
- 排队分组2 :1001-2000 号
- 排队分组3 :2001-3000 号
上面提到的“虚空分组”对应了上图中被涂成黄色的的分组,在实际应用中,这个分组其实是不需要的,因为这个分组会在第一次发散轮盘进行跨层级发散时发散到上一个层级中,这不过为了方便理解,我把这些“虚空分组”画了出来。
至此,车站已经初始化好了这个“时间轮”模型,现在开始转动“时间轮”,即安检机开始逐个安检,大致过程如下:
- 当 1-10 号乘客完成安检后,则向『安检排队』获取下一个
排队分组 2,即 11-20 号乘客,以此类推; - 当安检排队中的最后一个(第100号)乘客通过安检后,则向『验票通道』获取下一个
排队分组 2,即 101-200 号乘客,并将这 100 个乘客做一次发散处理(101-110 发撒到『安检通道』,111-200分别发散到『安检排队』分组2-10); - 当第 1000 号乘客通过安检后,则发散 1001-2000 号乘客,处理方式与步骤 2 类似;
定时器实现
skynet 的定时器实现属于分层时间轮,分为了 4 个发散轮盘(64个槽位)和 1 个工作轮盘(256个槽位),因此它的最大能表示的轮回时间为:64*64*64*64*256 = 4294967296,刚好为一个 uint32 能表示的数字的个数(0 ~ 0xFFFFFFFF)。需要注意一点,在 skynet 中,框架层只提供了定时器的添加,并没有提供定时器撤销的接口,原因嘛,因为云风坚持:“框架只应该提供必不可少的特性,能用已有的特性实现的东西都应该删掉”。若需要撤销某个 timer,可以在应用层忽略对应的定时事件即可。
skynet timer 结构体关系图如下: 
首先,我们来剖析下 timer 的核心结构,它的结构定义如下:
struct timer {
struct link_list near[256]; // 工作轮盘
struct link_list t[4][64]; // 发散轮盘
struct spinlock lock;
uint32_t time;
uint32_t starttime;
uint64_t current;
uint64_t current_point;
};
这里需要注意后面四个跟时间相关的字段,它们的意义和作用各不相同:
time,表示时间轮转动次数,当时间轮走完一整个轮回后,该字段会重置为 0,继续轮回;starttime,表示定时器初始化时的时间戳(单位为秒),该时间戳获取后将不会变化;current,表示从starttime开始,经过了多少厘秒(1/100 秒),只增不减;current_point,表示以厘秒为单位的本机当前时间戳,可增(本机时间往前调)可减(本机时间往回调);
根据上面这四个字段,可以得到下面几个信息:
- 在 skynet 进程中获取当前时间戳(秒)的公式为
timer->starttime + timer->current/100; - 在 skynet 进程中获取的当前时间戳只增不减,且不一定等于物理机上的当前时间戳(物理机的时间可能被人为修改);
- 若物理机的时间被往前调大后,定时器会在一个逻辑帧内快速 tick,以此弥补定时事件,例如物理机时间从 0s 修改为 1s,则定时器则在一帧内快速 tick 100次;
- 若物理机的时间被往回调小后,定时器不会做任何回退操作,之前被触发的定时事件不会因为时间回退而再次被触发;
在 skynet 中,定时器的转动由 thread_timer 驱动,时间轮 tick(或称“滴答”) 一次的时间间隔为 10ms,timer 线程的处理逻辑如下:
static void *
thread_timer(void *p) {
struct monitor * m = p;
skynet_initthread(THREAD_TIMER);
for (;;) {
skynet_updatetime();
skynet_socket_updatetime();
CHECK_ABORT
wakeup(m,m->count-1); // 贪婪唤醒工作线程
usleep(2500); // 睡眠 2.5 ms
if (SIG) {
signal_hup();
SIG = 0;
}
}
// wakeup socket thread
skynet_socket_exit();
// wakeup all worker thread
pthread_mutex_lock(&m->mutex);
m->quit = 1;
pthread_cond_broadcast(&m->cond);
pthread_mutex_unlock(&m->mutex);
return NULL;
}
可以看到,虽然在定时器内是 10ms tick 一次,但是在 timer 线程中执行间隔为 2.5ms。
添加定时消息
当往定时器中添加一个定时事件时,这个定时事件的结构体该如何定义呢?在 skynet 中,一个定时事件由两个结构体合作表示:
// 定时事件
struct timer_event {
uint32_t handle; // 注册该事件的服务 handle id
int session; // 该定时消息的 session
};
// 事件节点,插入到定时列表中
struct timer_node {
struct timer_node *next;
uint32_t expire;
};
反应到内存布局上时,一个封装的定时事件对象结构如下:
+----------+------------+------------------------+
| | | +--------------------+ |
| next | expire | | handle | session | |
| | | +--------------------+ |
+----------+------------+------------------------+
当我们添加一个定时事件时,一般会传入事件的到期时间间隔或者 tick,那么,如何找到正确的槽位来添加这个定时节点呢?这就要用到前面提到的 timer->time 字段了,将定时节点的到期时间 timer_node->expire 与 time 逐层级对比,先找到合适的层级 level,再计算出正确的槽位索引 index。具体的添加逻辑如下:
static void
add_node(struct timer *T,struct timer_node *node) {
uint32_t time=node->expire;
uint32_t current_time=T->time;
// 这里我替换了 宏定义,方便阅读代码
if ((time|255)==(current_time|255)) {
link(&T->near[time&255],node);
} else {
int i;
uint32_t mask=256 << 6;
for (i=0;i<3;i++) {
if ((time|(mask-1))==(current_time|(mask-1))) {
break;
}
mask <<= TIME_L6EVEL_SHIFT;
}
int index = (time >> (8 + i*6)) & 63;
link(&T->t[i][index], node);
}
}
static void
timer_add(struct timer *T,void *arg,size_t sz,int time) {
struct timer_node *node = (struct timer_node *)skynet_malloc(sizeof(*node)+sz);
memcpy(node+1,arg,sz);
SPIN_LOCK(T);
// assert(time<=0xFC000000); //超时tick不能超过 0xFC000000
node->expire=time+T->time;
add_node(T,node);
SPIN_UNLOCK(T);
}
在上面的逻辑中,有一个小细节需要多多体会一下,当一个 timer_node 的到期时间发生溢出时,最终的 node 会被存放在 T->t[3][0] 这个槽位中,这里还有一个隐藏的条件约束:传入给 timer_add 函数的 time 参数的值不能大于 0xFC000000,这也是为什么这个参数的数据类型是 int 而不是 uint 的原因(因为 int 能表达的最大正数为 0x7FFFFFFF)。
为什么会有这个限制,通过下面的例子就一目了然了:
设:T->time = 0xFFFFFFFF;
现添加一个超时time = 0xFFFFFFFE 的定时事件,则:
node->expire = time + T->time = 0xFFFFFFFD;
执行 add_node 逻辑,得到的槽位为:T->near[0xFD] = T->near[253];
显然,上面的添加逻辑出现了错误!为了保证逻辑正确性,就需要保证溢出后的 node->expre 不能超过 0xFBFFFFFF,由此反推出超时间隔 time <= 0xFC000000。
此外,在添加定时器时,还有一个细节优化,即当传入一个超时间隔为 0 的定时事件时,会直接派发定时消息到对应的服务中,不再添加到时间轮中。这里也可以思考一下,如果没有这个过滤优化,定时器该如何处理 timeout 0 的定时器事件呢?
触发定时事件
在前面已经提到了定时器会以频率 1tick / 10ms 来转动时间轮,每转动一次会触发工作轮盘中对应槽位的定时事件,当工作轮盘转动完一整轮后,则触发发散操作。具体操作的代码实现如下:
// 为了方便阅读代码,便于理解,我对代码做了一些简单处理
static void
timer_update(struct timer *T) {
SPIN_LOCK(T);
// try to dispatch timeout 0 (rare condition)
//timer_execute(T);
// 派发定时消息
int idx = T->time & 255;
while (T->near[idx].head.next) {
struct timer_node *current = link_clear(&T->near[idx]);
SPIN_UNLOCK(T);
// dispatch_list don't need lock T
dispatch_list(current);
SPIN_LOCK(T);
}
// shift time first, and then dispatch timer message
// 转动轮盘,可能触发发散逻辑
timer_shift(T);
//timer_execute(T);
// 派发定时消息
int idx = T->time & 255;
while (T->near[idx].head.next) {
struct timer_node *current = link_clear(&T->near[idx]);
SPIN_UNLOCK(T);
// dispatch_list don't need lock T
dispatch_list(current);
SPIN_LOCK(T);
}
SPIN_UNLOCK(T);
}
整个执行逻辑的伪代码大致如下:
lock1(T);
清空 T->near[T->time & 255], 并返回链表头部指针 current1;
unlock1(T);
派发 current1 链表中的定时消息;
lock2(T);
转动轮盘(++T->time);
清空 T->near[T->time & 255], 并返回链表头部指针 current2;
unlock2(T);
派发 current2 链表中的定时消息;
lock3(T);
unlock3(T);
为什么会执行两次 timer_execute 呢?
回到上一节最后留下的那个疑问了,因为 timer 模块并不对 timeout 0 消息的处理做出承诺,也就说 timer 模块需要支持对 timeout 0 的正确处理,虽然 skynet 确实对 timeout 0 的消息做了过滤优化。下面还是通过一个示例来解释具体原因:
0 1 2 3
+ + + +
| | | |
+---------------------------------------------------------+
| | | |
| 10ms | 10ms | 10ms |
+ + + +
假设当前 T->time = 2,即时间轮转动了 2 次,经过 10ms 后,再次转动时间轮,即 T->time 从 2 变为 3,按照正常逻辑会进行如下操作:
lock(T);
转动轮盘(转动后 T->time = 3);
清空 T->near[3], 并返回链表头部指针 current;
unlock(T);
派发 current 链表中的定时消息;
但是,在这次 tick 过程中,一个细节处理就出现了!
因为 skynet 是一个多线程框架,在前一次时间轮转动(T->time 从 1 变为 2)之后,槽位 2 上的定时事件都会被处理完毕并清空,然后时间轮再等待 10ms 进行下一次转动,但是在这等待的 10ms 中,可能其他的工作线程会添加一些 timeout 0 的定时消息(假设 skynet 没有过滤掉 timeout 0 消息),而此时 T->time = 2,因此这些新添加的定时消息又会插入到槽位 2 中,当下一次转动发生后(T->time=3),槽位 2 上的那些定时消息就失去了触发的机会,从而导致定时事件丢失。这就是为什么 timer_execute 需要执行两次的原因。
需要说明一点,我个人认为上面的处理可能存在一个问题(也许是我没有理解正确,如有错误请指正): 在 unlock1(T) 到 lock2(T) 的过程中,依然可能会出现工作线程插入 timeout 0 消息的情况。
我的解决方案如下:
static void
timer_update(struct timer *T) {
SPIN_LOCK(T);
struct timer_node *current1 = NULL;
struct timer_node *current2 = NULL;
int idx = T->time & 255;
while (T->near[idx].head.next) {
current1 = link_clear(&T->near[idx]);
}
timer_shift(T);
int idx = T->time & 255;
while (T->near[idx].head.next) {
current2 = link_clear(&T->near[idx]);
SPIN_UNLOCK(T);
}
dispatch_list(current1);
dispatch_list(current2);
}