CC BY 4.0 (除特别声明或转载文章外)
在深入服务模块时,先思考下面两个问题:
- 服务实例是怎么创建出来的?
- 消息怎么插入到队列并消费的呢?
带着这两个问题,我们开始一步步剖析 skynet 的服务模块。在这之前,先放出一张图,这张图描述了 skynet 服务模块的数据结构。

接下来,我会分成服务的创建、消息的处理以及服务的回收三个部分来深入服务模块。
服务创建流程
这一部分所说的创建不仅仅指服务对象的创建,还包括其消息队列的创建、服务模板动态库,同时还会介绍他们初始化的过程,以及在整个创建并初始化的过程中,需要注意的点及其原因。
服务上下文
首先,要描述一个叫做 『服务上下文』 的东西(我把它称之为 服务上下文- -,也就是 context),可以说它是 skynet 底层中非常重要的一个东西,基本上绝大部分的逻辑都是在围绕这个上下文进行。我们知道 skynet 是一个 Actor 模型的框架,所谓的“服务”本质就是一个 Actor,在上一篇文章中,我描述了一个等式:
一个 Actor 的参与者 = {消息队列, 处理逻辑(服务实例)}
那在 skynet 底层中,如何描述一个 Actor 参与者呢? 通过上面的结构体关系图可知,其实在 skynet 底层使用了结构体 struct skynet_context 来描述一个 Actor 参与者,这个结构体的定义如下:
struct skynet_context {
void * instance; // 服务实例
struct skynet_module * mod; // 动态库
void * cb_ud; // 用于回调的实例
skynet_cb cb; // 回调函数
struct message_queue *queue; // 服务消息队列
FILE * logfile; // for 服务日志
uint64_t cpu_cost; // in microsec,for cpu 性能指标
uint64_t cpu_start; // in microsec,for cpu 性能指标 & 当前消息处理耗时
char result[32]; // 存放性能指标的查询结果
uint32_t handle; // 服务的id
int session_id; // 消息的session id分配器
int ref; // 服务引用计数
int message_count; // 已处理过的消息总数
bool init; // 初始化成功的标识
bool endless; // 死循环标识
bool profile; // cpu 性能指标开启开关
CHECKCALLING_DECL
};
这个结构体有四个重要的字段:
instance,它是一个指针,指向了一个服务对象,它是由服务模板struct skynet_module * mod创建出来的cb,服务的回调函数,是消息被服务对象执行的唯一通道,这个回调函数可以重新设置queue,它是一个指针,指向了消息队列对象,这个对象中的q->queue字段才真正存放了消息数组cb_ud,它是一个被回调函数真实调用的服务实例对象的指针
就是上面的四个字段,才构成了一个 Actor 核心骨架,消息队列内的消息被服务的回调函数 cb 执行,这也是为什么说 skynet 是消息驱动的。一个大致的流程是:一个消息通过服务的回调函数,然后传递给服务实例,最终被消费处理掉。回调函数原型如下:
// 回调函数类型
typedef int (*skynet_cb)(struct skynet_context * context, void *ud, int type, int session, uint32_t source , const void * msg, size_t sz);
这里需要注意下,在服务实例第一次初始化并设置回调后,cb_ud 与 instance 是同一个东西,即ctx->instance = ctx->cb_ud,但是对于 snlua 服务启动后,会重新设置一次回调,这里就产生了两个区别的:
cb_ud指向由原来的ctx->instance变成了 lua vm(lua 主线程),它们存在这样的一个关系:ctx->instance->L = ctx->cb_ud = luavm;cb回调函数变成了一个封装了 lua 调用的函数;
具体的更改流程的代码我贴在了下面:
static int
lcallback(lua_State *L) {
struct skynet_context * context = lua_touserdata(L, lua_upvalueindex(1));
int forward = lua_toboolean(L, 2);
luaL_checktype(L,1,LUA_TFUNCTION);
lua_settop(L,1);
lua_rawsetp(L, LUA_REGISTRYINDEX, _cb);
lua_rawgeti(L, LUA_REGISTRYINDEX, LUA_RIDX_MAINTHREAD);
lua_State *gL = lua_tothread(L,-1);
if (forward) {
// cb_ud=gL
// cb = forward_cb,消息派发后不free掉,用于转发消息
skynet_callback(context, gL, forward_cb);
} else {
// cb = _cb,消息派发后free掉
skynet_callback(context, gL, _cb);
}
return 0;
}
创建上下文
在上一节展示了服务上下文的结构体,接下来看下服务上下文的创建和初始化流程,下图是一个服务上下文的详细创建过程。 
整个流程都封装在 skynet_context_new 这个函数中,函数实现如下:
struct skynet_context *
skynet_context_new(const char * name, const char *param) {
struct skynet_module * mod = skynet_module_query(name);
if (mod == NULL)
return NULL;
void *inst = skynet_module_instance_create(mod);
if (inst == NULL)
return NULL;
struct skynet_context * ctx = skynet_malloc(sizeof(*ctx));
CHECKCALLING_INIT(ctx)
ctx->mod = mod;
ctx->instance = inst;
ctx->ref = 2; // 思考为什么是 2
ctx->cb = NULL;
ctx->cb_ud = NULL;
ctx->session_id = 0;
ctx->logfile = NULL;
ctx->init = false;
ctx->endless = false;
ctx->cpu_cost = 0;
ctx->cpu_start = 0;
ctx->message_count = 0;
ctx->profile = G_NODE.profile;
// Should set to 0 first to avoid skynet_handle_retireall get an uninitialized handle
ctx->handle = 0;
ctx->handle = skynet_handle_register(ctx);
struct message_queue * queue = ctx->queue = skynet_mq_create(ctx->handle);
// init function maybe use ctx->handle, so it must init at last
context_inc();
CHECKCALLING_BEGIN(ctx)
int r = skynet_module_instance_init(mod, inst, ctx, param);
CHECKCALLING_END(ctx)
if (r == 0) {
// 初始化成功
struct skynet_context * ret = skynet_context_release(ctx);
if (ret) {
ctx->init = true;
}
skynet_globalmq_push(queue);
if (ret) {
skynet_error(ret, "LAUNCH %s %s", name, param ? param : "");
}
return ret;
} else {
// 初始化失败,回收 ctx
skynet_error(ctx, "FAILED launch %s", name);
uint32_t handle = ctx->handle;
skynet_context_release(ctx);
skynet_handle_retire(handle);
struct drop_t d = { handle };
skynet_mq_release(queue, drop_message, &d);
return NULL;
}
}
此函数一共有三个地方调用,其中有两处是在 skynet 启动过程中(skynet_start)调用,这两个函数调用会创建两个重要的服务:
- logger 服务,用来输出 skynet 的日志信息到文件(由配置字段
logger指定)或标准输出(stdout),当然,我们可以重载 skynet 自带的 logger 服务,修改配置字段logservice即可。 - bootstrap 服务,是一个 lua 服务,它负责引导基础服务,例如 launcher 服务等,它的作用类似于电脑开机时的引导程序一样。
前面两处调用都是用来初始化 skynet 进程所需的核心服务,而第三处调用是为了支持在已经启动的服务实例中能方便的启动其他服务,skynet 底层进一步对上面的流程进行封装,然后把封装好的接口暴露个上层使用,类似于 linux 内核暴露出的系统调用。
封装的服务启动接口原型如下:
static const char *
cmd_launch(struct skynet_context * context, const char * param);
这个接口接收一个 const char *param 的参数,它用来控制skynet 应该启动一个什么服务,以及服务启动时的参数,服务类型名称和服务参数用空格分隔。例如,传递参数是 "snlua launcher",则表示启动一个 launcher 的 lua 服务(这个服务专门负责 lua 层的服务启动,是一个非常重要的服务)。
下图是 launcher 服务创建一个新服务的调用图: 
launcher 服务
创建好的 context 会被注册到服务仓库 handle_storage *H 中,如果注册成功,会给 context 分配一个 handle (即服务上下文的id,类似与文件描述符id),handle 是一个无符号 32 位整型,高 8 位用来表示 harbor_id,低 24 位则表示 context 的索引号 index,即:handle=(harbor_id<<24)|index。需要注意的是,这两部分值都需要大于 0,即:harbor_id>0 && index>01;然后创建服务的消息队列 queue,至此,服务已经创建完成,接下来便是服务的初始化过程。
服务初始化过程,其实是一个服务差异化的过程,每个创建好的服务实例通过传入参数的不同,会有不同的设置,这一部分会在接下来的汽车工厂的例子有更多详细的讲解。 然后设置服务的回调,最后把服务的消息队列 push 到全局消息队列中,以被工作线程消费、执行。
服务模板
所谓的服务模板(我暂且这么命名ƪ(˘⌣˘)ʃ),有点像一个工厂类,一个服务模板可以创建和初始化一个或多个服务实例,同时在创建服务实例时传递一些参数,对其进行一些定制操作。
套用现实生活场景中,一个汽车工厂可以生产很多辆汽车,每一辆生产出来的汽车就相当于一个服务实例,当然,工厂可以在生产汽车时,为了满足客户需求,提供一些可控的定制化服务,例如:车身颜色定制、配件增加等,而其中用来生产汽车的流水线就是一个服务模板。
在 skynet 中,这些模板是以动态库的形式存在,这些服务模板动态库编译后存放在 cservice 目录,目前,skynet 已有四个服务模板,它们分别是:
- logger,日志服务模板,在上面已经有提到;
- gate,网关服务模板,最新版的 skynet 已经有另外一套 lua gate 实现方案;
- harbor,提供 master/slave 模式的集群方案;
- snlua,所有的 lua 服务都由它负责。
当然,所有的服务模板都需要遵守一些约定,它们需要提供以下 4 个 api:
- create,必须,此 api 用来创建对应的服务实例;
- init,必须,此 api 用来对服务实例进行初始化,同时还会设置 context 的回调实例和回调函数;
- release,必须,用来释放服务实例,做一些清理工作;
- signal,可选,用来跳出 lua 服务的死循环2。
以上的这些接口定义可以在 skynet_module.h 头文件中找到。
// api 原型
typedef void * (*skynet_dl_create)(void);
typedef int (*skynet_dl_init)(void * inst, struct skynet_context *, const char * parm);
typedef void (*skynet_dl_release)(void * inst);
typedef void (*skynet_dl_signal)(void * inst, int signal);
// 服务模板结构
struct skynet_module {
const char * name;
void * module;
skynet_dl_create create;
skynet_dl_init init;
skynet_dl_release release;
skynet_dl_signal signal;
};
另外,在 skynet_context_new 过程中,服务模板的查询是动态加载的,也就是说,在执行 query 时才去模板仓库 modules *M 中查找,如果未找到,则尝试加载对应的动态库,具体加载流程在 skynet_module_query 中。
消息队列
一个服务实例一定有一个服务消息队列(很多人称之为次级消息队列)与之对应,它的实现方式是一个环形队列。

服务消息队列
消息队列的容量默认是 64,若容量不足则以 2 倍的方式进行增长,另外,当消息队列中堆积的消息过载,则每次达到 1024 的整数倍时,由监控线程发出警报。
监控相关
关于服务上下文的一些核心已经在上面基本介绍的差不多了,最后介绍一下 context 的一些小细节或辅助功能,它们会关联在结构体 struct skynet_context 上的一个或多个字段,利用好这些功能,对我们分析查找问题有很大的帮助。
服务日志
这个功能可以把服务处理过的消息都导出到一个文件中,配合 debug console 的 logon 和 logoff 两个命令使用,这个功能可以帮助我们对某个指定的服务进行问题查找,下面是用 skynet 的 example 做了一个演示。
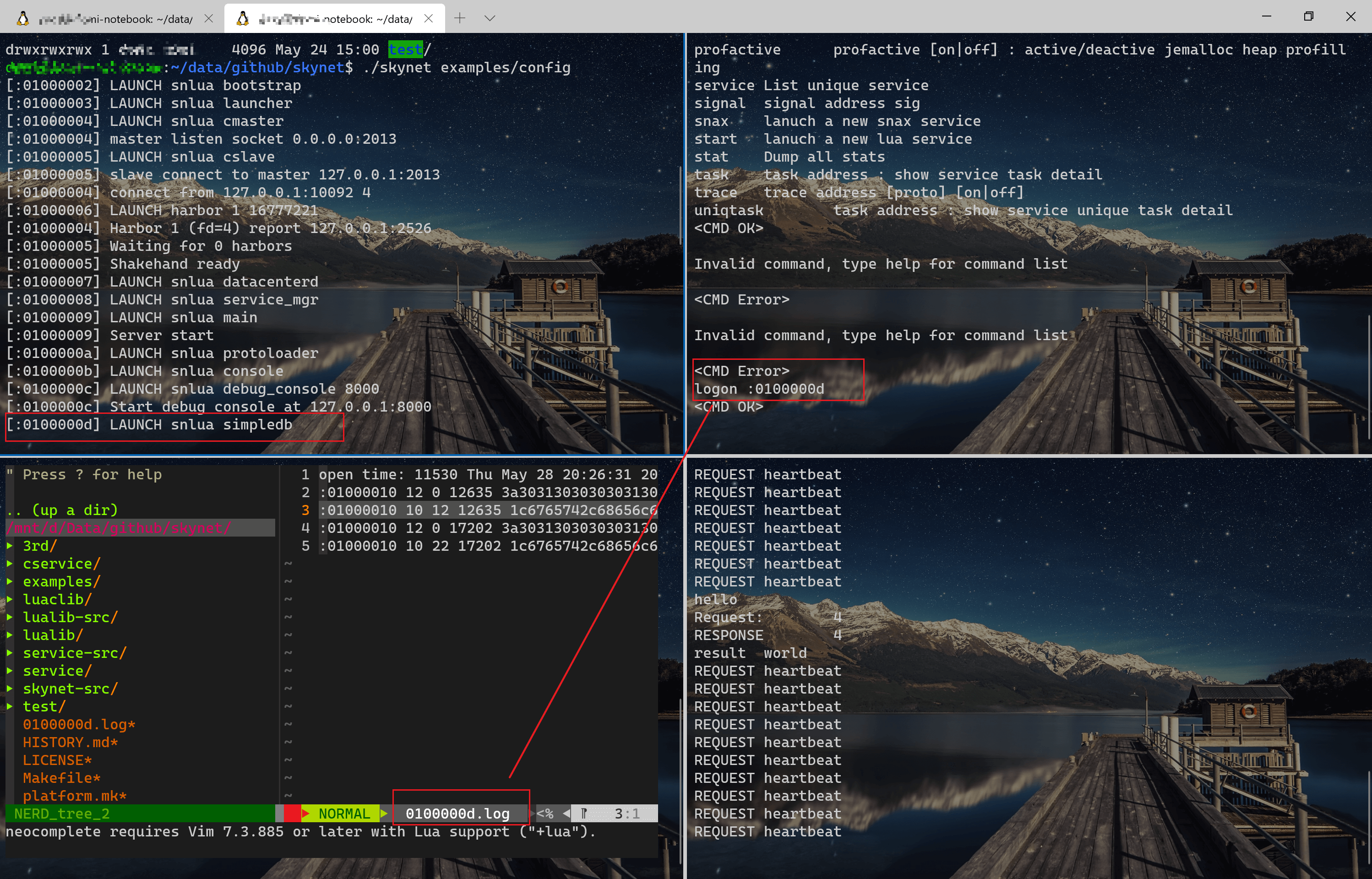
性能指标
这些性能指标包括服务已经处理的消息总数、服务处理消息的 cpu 总耗时、是否出现死循环等,可以配合 debug console 的 stat 命令使用(都是调用了底层的 cmd_stat),下面是所有性能指标的名称和作用:
- cpu,表示这个服务处理消息消耗的 cpu 总耗时,毫秒为单位,由 profile 字段控制,默认开启,数值越大表示这个服务越繁忙;
- message,表示已经被这个服务处理过的消息总数;
- time,这个指标可以计算出某个服务当前正在处理的消息已耗时长,可以用来检测一个服务的某个逻辑耗时是不是过长,一般情况为 0,如果值较大就需要注意了,是不是由业务逻辑有问题,可能死循环或者逻辑计算过大;
- endless,若为 1 则表示服务长时间没有进行消息处理,可能出现了死循环,也可能是出现 endless 的前一个逻辑耗时超过 5s,它的值是由监控线程设置;
- mqlen,表示服务当前还未处理的消息数量,如果消息堆积过多,会出现
May overload, message queue lenght=xxx的错误日志,详细机制会在后面的消息处理部分详细讲解; - task,这一个指标较为特殊,它不是由底层提供,它的值需要在 lua 层获取,表示某个服务当前挂起的 coroutine 数量。
消息处理流程
注意,先停一停,从 skynet 的代码世界中跳出来,先思考一个现实生活中快递站点的场景:
有一个快递配送点,每天会把要派送的包裹分成多堆存放在不同仓库或角落,每一堆表示这个站点配送范围内的一个片区,且每一堆包裹由一个快递小哥负责用三轮车进行配送,假如你是这个配送站的负责人,你当然是希望快递尽可能快速、合理的被配送,那应该采用什么方案呢?
最直接的办法是让一个快递员固定负责一个片区,但是如果负责的片区过多,需要的快递员就会增多,这样人力成本就会上升。改进的办法是让快递员不固定在一个片区内,而是在送完一个片区的包裹后,如果其他片区还没有人在负责配送,则动态分配到其他片区,不过这里还是会存在一个问题,如果某个快递员在派送其中一个片区的快递时,又有新的包裹添加进来,这时问题产生了:这个片区一直在进行包裹的配送,而其他片区因为快递员不足导致包裹滞留(即“线程饿死”)。
我们对上面的方案再次进行改进:每个片区按照先后顺序排列,每个快递员按照顺序取出片区队列中的第一个片区并派送固定数量的包裹,配送完一批包裹后,如果这个片区还有未配送的包裹,就把这个片区重新插入到片区队列尾部,以此循环配送,每次的配送数量可以按照一定的规则来决定,例如三轮车大一点、动力好一点就配送多一些包裹。以这样的方式进行配送,既能保证每个片区的包裹都能得到派送,不至于长时间滞留,又能节约人力成本。
好,现在再回到 skynet 中的消息处理流程,它其实就是采用了类似快递配送的最后的改良方案,我对其进行一次转换,就一目了然。
片区队列 = 全局消息队列
片区仓库 = 服务消息队列
配送数量 = 一次派发的消息数量
分配派送流程 = 工作线程
要注意的是:消息并不存放在全局消息队列中,类似于包裹是被堆积在不同的片区仓库内,只是这个片区被插入到片区队列内,真正的消息是存放在服务消息队列(或称次级消息队列)中;另外,关于派发消息数量,skynet 用一套权重 weight 规则来计算,后面会详细讲解
工作线程
skynet 有四类线程,其中只有工作线程创建多个,它由配置中的 thread 字段控制,如果不配置默认为 8。此线程负责的逻辑非常简单,就是从全局消息队列中 pop 出一个服务消息队列,然后派发一定数量的消息。它的大致流程如下图所示: 
具体的代码实现在函数 skynet_context_message_dispatch 中。
struct message_queue *
skynet_context_message_dispatch(struct skynet_monitor *sm, struct message_queue *q, int weight) {
if (q == NULL) {
q = skynet_globalmq_pop();
if (q==NULL)
return NULL;
}
uint32_t handle = skynet_mq_handle(q);
struct skynet_context * ctx = skynet_handle_grab(handle);
if (ctx == NULL) {
struct drop_t d = { handle };
skynet_mq_release(q, drop_message, &d);
return skynet_globalmq_pop();
}
int i,n=1;
struct skynet_message msg;
for (i=0;i<n;i++) {
if (skynet_mq_pop(q,&msg)) {
skynet_context_release(ctx);
return skynet_globalmq_pop();
} else if (i==0 && weight >= 0) {
n = skynet_mq_length(q);
n >>= weight;
}
int overload = skynet_mq_overload(q);
if (overload) {
skynet_error(ctx, "May overload, message queue length = %d", overload);
}
skynet_monitor_trigger(sm, msg.source , handle);
if (ctx->cb == NULL) {
skynet_free(msg.data);
} else {
dispatch_message(ctx, &msg);
}
skynet_monitor_trigger(sm, 0,0);
}
assert(q == ctx->queue);
struct message_queue *nq = skynet_globalmq_pop();
if (nq) {
// If global mq is not empty , push q back, and return next queue (nq)
// Else (global mq is empty or block, don't push q back, and return q again (for next dispatch)
skynet_globalmq_push(q);
q = nq;
}
skynet_context_release(ctx);
return q;
}
虽然整体逻辑较为简单,不过在其实现过程中还是有几个点可以拿出来研究一番。
动态唤醒
首先要知道一个原则:全局消息队列内是存放的诸多不为空的服务消息队列,也就是说没有消息的服务是不会把它的消息队列 push 进全局队列中的3(除了服务创建时的第一次 push)。那我们思考一个问题:因为工作线程数量有限,而活跃的服务(有消息且在全局队列中)数量是不定的,当它们的比例关系 m(工作线程):n(活跃服务) 小于等于 1 时,表示每个线程都处于工作中;而如果这个比例大于 1 时,则表示工作线程有空余,套用上面快递员的例子,就是存在一些快递员没有包裹需要派送,处于休息状态。
此时,如果不对这些空闲线程做挂起操作,就会浪费 CPU 资源,进而浪费电(→_→)。skynet 采取的策略是在全局消息队列为空时,使用条件变量(pthread_cond_t)来挂起工作线程,而对于线程的唤醒,一共有两处地方:
- 网络线程唤醒,采用“懒惰唤醒”,即只有在所有工作线程都挂起时,才会唤醒一个。举个栗子,如果有 8 个工作线程,其中 7 个都处于挂起状态,那么在网络线程收到网络消息后,也不会进行唤醒,除非 8 个工作线程都被挂起;
- 定时器线程唤醒,采用“贪婪唤醒”,即只要有工作线程处于挂起状态,就会唤醒一次;另外在定时器线程结束后,还会广播唤醒所有挂起的工作线程;
均衡派发
均衡派发是指在处理多个服务的消息队列时,尽量做到“雨露均沾”,以此来解决上面提到的“线程饿死”的情况。skynet 会给每个工作线程一个权重值 weight,根据这个权重值计算出工作线程每次应该处理的消息数量 n,计算方式如下:
if weight > 0 then
n = 消息队列当前容量 >> weight
elseif weight == 0 then
n = 消息队列当前容量
elseif weight < 0 then
n = 1
end
也就是说,当 weight<0时,每次处理一个消息,当 weight==0 时,每次会处理完“当前队列”中的所有消息,而当 weight>0 时,每次处理“当前队列”容量的 1/(2^weight),权重值越大,每次处理的消息越少。注意:这里所说的“当前队列”容量是指在处理第一个消息时,该时刻服务消息队列的消息容量,本质上是一个“过去时”的值,这也是为什么“当前队列”要加引号的原因。
插入消息
在 skynet 中,服务之间传递的消息都被封装成统一的格式,不论是网络消息还是定时器消息,消息结构体如下:
struct skynet_message {
uint32_t source;
int session;
void * data;
size_t sz;
};
source 表示发出这个消息的服务 handle id,如果一个服务收到了一个 source=0 的消息,则表示这个消息是不是从一个服务实例中发出的,例如定时器消息和网络消息,或者发出这个消息的服务实例已经被销毁;
session 表示这个消息的序列号,类似 TCP 数据报(segment)的 SEQ,需要注意的是每一个请求包才需要生成一个新的 session,而返回包是不需要生成新的 session,只需要把请求包的 session 在返回时赋值给返回包即可,当然,需要标识这个包是一个返回包,接下来就会说到消息包的类型,一个消息包session的生成规则会涉及到 ctx 的 session_id 字段,具体生成逻辑这里不赘述,查看源码即可;
data 它是一个指针,指向了消息携带数据真正的内存地址,可以为空指针,即没有消息数据,对于一个从 lua 服务中传递过来的消息数据(在 lua 中使用了 c.send),可以是 LUA_TSTRING 和 LUA_TLIGHTUSERDATA,前者必须做一次内存拷贝(原因请查阅 lua_tolstring 的说明文档),而后者则不需要。关于这个数据指针的 free,将会在接下来的『消息消费』中深入探讨。
sz 字面意思是消息数据的长度,但其实该字段除了包含了数据的长度,还携带了另外一个信息,就是这个消息的类型,消息类型的定义可以在 skynet.h 头文件中找到,它用 sz 的高 8 位(1 byte)来表示,例如在 64 位系统下 sz = 消息类型<<56 | 数据长度。
上面已经对 skynet 的消息结构有了一个全方位的了解,对于如何把一个消息插入到目的服务的消息队列中,已经没有太多需要深入的细节。可能唯一需要注意的是,当一个消息插入到服务的消息队列中时,如果这个服务处于“非活跃”状态(即没有加入到全局消息队列),那么会将该服务重新触发为“活跃”状态,实现细节在 skynet_mq_push。
void
skynet_mq_push(struct message_queue *q, struct skynet_message *message) {
assert(message);
SPIN_LOCK(q)
q->queue[q->tail] = *message;
if (++ q->tail >= q->cap) {
q->tail = 0;
}
if (q->head == q->tail) {
expand_queue(q);
}
if (q->in_global == 0) {
q->in_global = MQ_IN_GLOBAL;
skynet_globalmq_push(q);
}
SPIN_UNLOCK(q)
}
消息消费
消息处理的过程已经在前面讲解的差不多了,其过程也较为简单,即服务通过注册的回调函数来处理收到的消息,回调函数(skynet_cb)的定义可以在 skynet.h 中找到(在前面也已经提到),它接收 7 个参数:
- context,表示处理该消息的服务上下文;
- ud,表示真正处理该消息的服务实体指针(不一定是服务实例,也可以是服务实例内的其他元素,例如 snlua 服务实例的 lua 虚拟机指针);
- type,消息的类型(上文已提到);
- session,消息的序列号;
- source,发生消息的源服务 handle id;
- msg,消息数据的指针;
- sz,消息数据的长度;
关于消息处理的一个原则是:一个消息的数据必须由最后处理该消息的服务进行回收处理。这是什么意思呢?下面通过一个例子来解释这条原则。
假如你的朋友小明给你送一盒橘子,你会有两种方式收到这一盒橘子并吃掉它们:
- 小明直接亲自送到你手上
- 小明用快递邮寄,通过快递员送到你的手上
不管通过哪一种方式,最终你会收到一盒橘子,然后吃掉它们,那吃完后剩下的橘子皮肯定是由你自己负责清扫,不可能让朋友小明或者快递员来给你处理(除非你想被打),在这一个流程中,你就是最后处理消息的人,你就需要负责最后的数据回收,快递员虽然也处理过这条消息,但是他是不能吃掉盒子内的橘子(即消息包中携带的数据)。
理解了上面的例子后,现在回头看看 skynet 的消息处理流程:
static void
dispatch_message(struct skynet_context *ctx, struct skynet_message *msg) {
assert(ctx->init);
CHECKCALLING_BEGIN(ctx)
pthread_setspecific(G_NODE.handle_key, (void *)(uintptr_t)(ctx->handle));
int type = msg->sz >> MESSAGE_TYPE_SHIFT;
size_t sz = msg->sz & MESSAGE_TYPE_MASK;
if (ctx->logfile) {
skynet_log_output(ctx->logfile, msg->source, type, msg->session, msg->data, sz);
}
++ctx->message_count;
/*
reserve_msg : 回调函数的返回值
reserve_msg = 1,表示不能释放消息数据 msg->data,只是做转发处理,在 clusterproxy 中有使用,lua 接口为 skynet.forward_type()
reserve_msg = 0,表示需要释放消息数据 msg->data,也说明这次是消息的终点
*/
int reserve_msg;
if (ctx->profile) {
ctx->cpu_start = skynet_thread_time();
reserve_msg = ctx->cb(ctx, ctx->cb_ud, type, msg->session, msg->source, msg->data, sz);
uint64_t cost_time = skynet_thread_time() - ctx->cpu_start;
ctx->cpu_cost += cost_time;
} else {
reserve_msg = ctx->cb(ctx, ctx->cb_ud, type, msg->session, msg->source, msg->data, sz);
}
if (!reserve_msg) {
skynet_free(msg->data);
}
CHECKCALLING_END(ctx)
}
这里要注意回调函数 ctx->cb 的返回值,当 reserve_msg = 1 时,表示不需要 free 消息数据,只是负责转发这个消息;当 reserve_msg = 0 时,在回调结束后,会 free 消息数据。而对于 snlua 服务来说,是否开启转发是由 api c.callback 的第二个参数决定的,例如 c.callback(func, true) 则表示开启转发(具体参见 skynet.forward_type)。
这里还涉及到了一个多线程的知识点:线程局部存储(Thread-Local Storage)(我将会在后续博文详细聊一聊),用于在工作线程中获取当前正在处理的服务 handle:
uint32_t
skynet_current_handle(void) {
if (G_NODE.init) {
void * handle = pthread_getspecific(G_NODE.handle_key);
return (uint32_t)(uintptr_t)handle;
} else {
uint32_t v = (uint32_t)(-THREAD_MAIN);
return v;
}
}
服务回收流程
服务的回收过程可以分为三个部分:服务实例的回收、服务消息队列的回收以及服务上下文(ctx)的回收,整个回收过程在 delete_context 函数中实现。
static void
delete_context(struct skynet_context *ctx) {
// 如果服务有日志文件,先关闭该日志文件
if (ctx->logfile) {
fclose(ctx->logfile);
}
// 回收服务实例
skynet_module_instance_release(ctx->mod, ctx->instance);
// 标记服务消息队列为“可回收(release)”
skynet_mq_mark_release(ctx->queue);
CHECKCALLING_DESTROY(ctx)
// 回收ctx
skynet_free(ctx);
context_dec();
}
需要指出的是,服务消息队列的回收方式稍微特殊一点,消息队列的内存并不会立即被 free 掉,还需要处理回收前遗留在队列中的消息,我会在接下来章节详细展开。
引用计数
skynet 使用引用计数的方式来决定是否销毁一个服务上下文,这有点类似 C++ 的智能指针,当 ctx->ref = 0 时,则会触发服务 ctx 的销毁流程。在代码中会发现 skynet_handle_grab 和 skynet_context_release 基本都是成对出现,前者引用一次 ctx(引用次数 +1),后者释放一次引用(引用次数 -1)。
struct skynet_context *
skynet_handle_grab(uint32_t handle) {
struct handle_storage *s = H;
struct skynet_context * result = NULL;
rwlock_rlock(&s->lock);
uint32_t hash = handle & (s->slot_size-1);
struct skynet_context * ctx = s->slot[hash];
if (ctx && skynet_context_handle(ctx) == handle) {
result = ctx;
skynet_context_grab(result); // ctx 引用次数 +1
}
rwlock_runlock(&s->lock);
return result;
}
struct skynet_context *
skynet_context_release(struct skynet_context *ctx) {
if (ATOM_DEC(&ctx->ref) == 0) {
delete_context(ctx); // ctx 引用次数等于0,则触发回收流程
return NULL;
}
return ctx;
}
这里回顾一下前面提到的服务 ctx 创建过程,思考一下为什么初始的 ctx->ref 要设置为 2,为什么不是 0 或者 1 呢?
首先,若 ref 设置为 0,肯定是错误的,因为在 ctx 注册到服务仓库 handler_storage *H中时,ctx 其实就已经被引用一次了,也就是说创建并注册成功的 ctx,其引用计数至少是 1。那为什么不直接设置 ctx 的 ref 为 1,而要设置为 2 呢?原因是 skynet 需要在 ctx 初始化后再次确保其是否是真实可用状态,举个例子:一个新的 ctx 在工作线程 A 中被创建,在 ctx 执行初始化操作后,若它在工作线程 B 中意外被减少一次引用(例如被执行了 kill),此时就会在线程 A 中出现一个已经被回收的 ctx 被 push 到全局消息队列的情况。
回收消息队列
服务消息队列的回收过程与服务实例回收和服务 ctx 回收相比会稍微复杂一点,不仅仅需要回收消息队列的内存,还需要处理队列中遗留的消息,要给这些遗留的消息的发送服务一个错误反馈,这就像你从一家公司离职后,当有之前的老客户和你联系时,你需要告知别人“我已经离职了”,而不是没有任何反馈信息。
消息队列的回收过程分为两个步骤:
- 标记要回收的消息队列(
skynet_mq_mark_release),并把它 push 到全局消息队列中; - 工作线程执行
skynet_mq_release,使用指定的丢弃函数(drop_message)来处理队列中遗留的消息包;
回收函数 skynet_mq_release 和丢弃函数 drop_message 的函数定义如下:
void
skynet_mq_release(struct message_queue *q, message_drop drop_func, void *ud) {
SPIN_LOCK(q)
if (q->release) {
SPIN_UNLOCK(q)
// 循环pop剩余的消息,并drop掉
_drop_queue(q, drop_func, ud);
} else {
skynet_globalmq_push(q);
SPIN_UNLOCK(q)
}
}
static void
drop_message(struct skynet_message *msg, void *ud) {
struct drop_t *d = ud;
skynet_free(msg->data);
uint32_t source = d->handle;
assert(source);
// report error to the message source
skynet_send(NULL, source, msg->source, PTYPE_ERROR, 0, NULL, 0);
}
可以看到,整个回收过程就是一个把遗留的消息一个个 pop 出来,再由丢弃函数向消息源服务发送一个错误消息,最后释放掉消息队列的内存。
总结
通过对服务的创建、服务的执行和服务的回收这三个过程的抽丝剥茧,基本上已经对 skynet 的整个服务模块以及消息处理流程有了一个全方位的了解,这也是 skynet 的核心,有了对核心的深入理解,相信对于后续的定时模块、网络模块等的理解将会驾轻就熟。
参考: