CC BY 4.0 (除特别声明或转载文章外)
目录:
- 第1章:入门
- 第2章:程序结构
- 第3章:基础数据类型
- 第4章:复合数据类型
- 第5章:函数
- 第6章:方法
- 第7章:接口
- 第8章:Goroutines和Channels
- 第9章:基于共享变量的并发
- 第10章:包和工具
- 第11章:测试
- 第12章:反射
- 第13章:底层编程
本书中文版,点这里。
接触golang也有两三年了,一直没有系统把它过一遍,正好通过这本书系统性的复习一次,掌握golang的细节。
第1章:入门
命令行参数
os包以跨平台的方式,提供了一些与操作系统交互的函数和变量。程序的命令行参数可从os包的Args变量获取;os包外部使用os.Args访问该变量。os.Args的第一个元素,os.Args[0], 是命令本身的名字(例如:D:\Github\xlsxconv\xlsxconv.exe)。bufio包,它使处理输入和输出方便又高效。Scanner类型是该包最有用的特性之一,它读取输入并将其拆成行或单词;通常是处理行形式的输入最简单的方法。它是按流模式读取输入,并根据需要拆分成多个行。理论上,可以处理任意数量的输入数据。还有另一个方法,就是一口气把全部输入数据读到内存中,一次分割为多行,然后处理它们,需要使用ReadFile(来自于io/ioutil)和strings.Split。input := bufio.NewScanner(os.Stdin) for input.Scan() { // TODO ... }Printf格式字符串:占位符 备注 %d 十进制整数 %x, %o, %b 十六进制,八进制,二进制整数。 %f, %g, %e 浮点数: 3.141593 3.141592653589793 3.141593e+00 %t 布尔:true或false %c 字符(rune) (Unicode码点) %s 字符串 %q 带双引号的字符串”abc”或带单引号的字符’c’ %v 变量的自然形式(natural format),如果包含的#副词 %#v,它表示用和Go语言类似的语法打印值%T 变量的类型 %% 字面上的百分号标志(无操作数) 如果你的操作系统是Mac OS X或者Linux,那么在运行命令的末尾加上一个&符号,即可让程序简单地跑在后台,windows下可以在另外一个命令行窗口去运行这个程序。
Go语言里的switch可以不带操作对象;可以直接罗列多种条件,像其它语言里面的多个if else一样。这种形式叫做无tag switch(tagless switch);这和switch true是等价的。
func Signum(x int) int { switch { case x > 0: return +1 default: return 0 case x < 0: return -1 } }指针是可见的内存地址,&操作符可以返回一个变量的内存地址,并且
*操作符可以获取指针指向的变量内容,但是在Go语言里没有指针运算,也就是不能像c语言里可以对指针进行加或减操作(可以通过unsafe包进行指针运算,具体参考我的golang每日笔记)。
第2章:程序结构
go有25个关键字,30多个内建的预定义字,可以参考源码的
Go\src\builtin\builtin.go。go推荐使用 驼峰式 命名。
Go语言主要有四种类型的声明语句:var、const、type和func,分别对应变量、常量、类型和函数实体对象的声明。
用
new创建变量和普通变量声明语句方式创建变量没有什么区别,除了不需要声明一个临时变量的名字外,我们还可以在表达式中使用new(T)。换言之,new函数类似是一种语法糖,而不是一个新的基础概念。所以下面的两个newInt作用是相同的:func newInt() *int { return new(int) } func newInt() *int { var dummy int return &dummy }如果两个类型都是空的,也就是说类型的大小是0,例如struct{}和 [0]int, 有可能有相同的地址。所以谨慎使用大小为0的类型,因为如果类型的大小为0的话,可能导致Go语言的自动垃圾回收器有不同的行为,具体请查看runtime.SetFinalizer函数相关文档。
编译器会自动选择在栈上还是在堆上分配局部变量的存储空间,这个选择并不是由用var还是new声明变量的方式决定的(这与C语言是有区别的)。当返回一个局部变量的指针时,用Go语言的术语说,这个局部变量从函数中逃逸了。记住的是,逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。具体看下面的例子:
var global *int func f() { var x int x = 1 global = &x // 此时x被分配到堆上 } func g() { y := new(int) // 此时y分配在栈上 *y = 1 }数值变量也可以支持++递增和–递减语句,注意:go只有后置没有前置,因此
++i这种是错误的。另外:自增和自减是语句,而不是表达式,因此x = i++之类的表达式是错误的。nil可以赋值给任何指针或引用类型的变量(slice、map、chan)。
按照惯例,一个包的名字和包的导入路径的最后一个字段相同,例如
gopl.io/ch2/tempconv包的名字一般是tempconv。如果包中含有多个.go源文件,它们将按照发给编译器的顺序进行初始化,Go语言的构建工具首先会将.go文件根据文件名排序,然后依次调用编译器编译。
第3章:基础数据类型
Go语言将数据类型分为四类:基础类型、复合类型、引用类型和接口类型。
在Go语言中,%取模运算符的符号和被取模数的符号总是一致的,因此
-5%3和-5%-3结果都是-2。Go语言还提供了以下的bit位操作运算符,前面4个操作运算符并不区分是有符号还是无符号数:
&位运算 AND|位运算 OR^位运算 XOR&^位清空 (AND NOT)<<左移>>右移
关于左移和右移:请参考C语言笔记的位运算部分。
关于
&^运算符(a &^ b):此运算符是双目运算符,按位计算,功能等同于以a&(^b),如果右操作数的bit位为1,则将左操作数的对应bit位置零,类似一个掩码,用于置零对应的bit位。和它等价的c语言运算符表达式:等价于c语言里的&=~int a = 3; a &= ~1;注意fmt的两个使用技巧。通常Printf格式化字符串包含多个%参数时:
%之后的[1]副词告诉Printf函数再次使用第一个操作数%后的#副词告诉Printf在用%o、%x或%X输出时生成0、0x、0X前缀
o := 0666 fmt.Printf("%d %[1]o %#[1]o\n", o) // "438 666 0666" x := int64(0xdeadbeef) fmt.Printf("%d %[1]x %#[1]x %#[1]X\n", x) // Output: // 3735928559 deadbeef 0xdeadbeef 0XDEADBEEFGo语言提供了两种精度的浮点数,
float32和float64。一个float32类型的浮点数可以提供大约6个十进制数的精度,而float64则可以提供约15个十进制数的精度。float32的有效bit位只有23个,float64的有效bit位只有53个,其它的bit位用于指数和符号。函数math.IsNaN用于测试一个数是否是非数NaN,math.NaN则返回非数(不合法的数学结果)对应的值。注意,
不要用NaN做比较预算,因为NaN和任何数都是不相等的。nan := math.NaN() fmt.Println(nan == nan, nan < nan, nan > nan) // "false false false"字符串,每一门语言比较难以理解的都是字符串(个人感觉),golang中的字符串是一个基础类型(
string),它与C语言中的字符串有一些区别。golang中字符串底层实现如下:struct string { byte* str; int len; }因此,可以看出它和C语言字符串的区别,它并不是以
\0字符作为字符串结束的依据,因为它已经明确指出了字符串的长度len。另外需要注意的是,空字符在C语言和golang中的表示也是有区别的:C语言是\0,golang是\x00(fmt.Println("hello\x00world"))。字符串的值是不可变的:一个字符串包含的字节序列永远不会被改变,当然我们也可以给一个字符串变量分配一个新字符串值。
s := "aaa" s += "bbb" //合法 s[0] = 'c' //不合法,编译错误不可修改意味着:如果两个字符串共享相同的底层数据的话也是安全的。
字符串可以转换成
[]byte和[]rune,前者是转换成字符数组,后者是转换成Unicode码点数组。var s string = "abcd你好" sb:=[]byte(s) sr:=[]rune(s) fmt.Println(sb,sr)标准库中有四个包对字符串处理尤为重要:bytes、strings、strconv和unicode包。
- strings包提供了许多如字符串的查询、替换、比较、截断、拆分和合并等功能。
- bytes包也提供了很多类似string包功能的函数,但是针对[]byte类型。
- strconv包提供了布尔型、整型数、浮点数和对应字符串的相互转换,还提供了双引号转义相关的转换。
- unicode包提供了处理unicode相关的功能函数
一个常量的声明也可以包含一个类型和一个值,但是如果没有显式指明类型,那么将从右边的表达式推断类型。
const pi = 3.14159265358979 const noDelay time.Duration = 0 const timeout = 5 * time.Minute常量声明可以使用iota常量生成器初始化,它用于生成一组以相似规则初始化的常量,但是不用每行都写一遍初始化表达式。
type Weekday int const( Sunday Weekday = iota // 0 Monday // 1 Tuesday Wednesday Thursday Friday Saturday )Go语言的常量有个不同寻常之处。虽然一个常量可以有任意有一个确定的基础类型,例如int或float64,但是许多常量并没有一个明确的基础类型(只有常量可以是无类型的)。编译器为这些没有明确的基础类型的数字常量提供比基础类型更高精度的算术运算;可以认为至少有256bit的运算精度。
这里有六种未明确类型的常量类型,分别是无类型的布尔型、无类型的整数、无类型的字符、无类型的浮点数、无类型的复数、无类型的字符串。
第4章:复合数据类型
4-1、数组
golang的数组与C语言中的数组是一样的,都是分配在一块连续的、有固定长度的内存中。同时,它是slice实现的基础。
在数组字面值中,如果在数组的长度位置出现的是“…”省略号,则表示数组的长度是根据初始化值的个数来计算。
q:=[...]int{1,2,3} fmt.Printf("%T,%[1]v\n",q) // [3]int,[1 2 3]此外,还有另一种形式的数组字面值,可以指定某个索引的值,其他未指定的值,则初始化为零值。
x := [3]int{1:100} y := [...]int{9: -1} //数组长度为10 fmt.Println(x,y) // output: [0 100 0] [0 0 0 0 0 0 0 0 0 -1]关于数组的指针,golang和C语言是有所区别的,在C语言中,数组名可以表示指向数组起始位置的指针,而golang中数组的指针要明确指出数组类型。
b:=[5]byte{'a','b'} var ptr *[5]byte var ptr1 *[10]byte ptr = &b ptr1= &b // compile error: cannot use &b (type *[5]byte) as type *[10]byte in assignment fmt.Printf("%+v,%[1]T,%c,%c",ptr,(*ptr)[0],ptr[0]) // output: &[97 98 0 0 0],*[5]uint8,a,a
4-2、slice
切片是建立在数组的基础上,它是一个引用类型,一个切片由三个部分构成:指针、长度和容量。
// golang 1.5 底层的C实现 struct Slice { // must not move anything byte* array; // actual data uintgo len; // number of elements uintgo cap; // allocated number of elements };和数组不同的是,slice之间不能比较,因此我们不能使用==操作符来判断两个slice是否含有全部相等元素。slice唯一合法的比较操作是和nil比较。
a:=[5]int{1,2,3,4,5} b:=[5]int{1,2,3,4,5} fmt.Println(a==b) // 数组比较,output:true a:=[]int{1,2,3,4,5} b:=[]int{1,2,3,4,5} fmt.Println(a==b) // invalid operation: a == b (slice can only be compared to nil)一个零值的slice等于nil。一个nil值的slice并没有底层数组。一个nil值的slice的长度和容量都是0(同时底层的指针即为
NULL)。与任意类型的nil值一样,可以用[]int(nil)类型转换表达式来生成一个对应类型slice的nil值。var s []int // len(s) == 0, s == nil s = nil // len(s) == 0, s == nil s = []int(nil) // len(s) == 0, s == nil s = []int{} // len(s) == 0, s != nil,这里要特别注意如果要测试一个slice是否是空的,使用len(s) == 0来判断,而不应该用s == nil来判断。另外需要注意一点,对一个切片赋值nil,并不是说这个切片没有在内存中存在,nil切片其实在内存中有分配空间,只是说它底层结构中,指针指向了NULL,len和cap为0。
var s []int = nil fmt.Printf("%p\n",&s) // output: 0xc0420483c0切片append,需要记住一个重要的点:append函数返回值必须有变量接收。原因是:append会导致底层结构发生变化。
要弄明白其中的原因,首先要知道一点,golang中所有的函数调用都是值传递。所谓的引用传递在底层中也是用值传递实现的。现在来看一下append函数的原型:
// The append built-in function appends elements to the end of a slice. If // it has sufficient capacity, the destination is resliced to accommodate the // new elements. If it does not, a new underlying array will be allocated. // Append returns the updated slice. It is therefore necessary to store the // result of append, often in the variable holding the slice itself: // slice = append(slice, elem1, elem2) // slice = append(slice, anotherSlice...) // As a special case, it is legal to append a string to a byte slice, like this: // slice = append([]byte("hello "), "world"...) func append(slice []Type, elems ...Type) []Type传入的slice这个变量其实在append内部是操作一个副本(只是说slice是个引用类型,但是传递参数还是值传递),append一个元素后,底层的len发生了变化,但是这个变化并没有反应到外部传入的那个源slice。所以,append在操作完后,一定要返回一个新的slice。
4-3、map
map中所有的key都有相同的类型,所有的value也有着相同的类型,但是key和value之间可以是不同的数据类型。其中K对应的key必须是支持==比较运算符的数据类型(所以切片不能作为map的key),所以map可以通过测试key是否相等来判断是否已经存在。
禁止对map内的元素进行取地址操作,因为map可能会因为元素的增长,而重新分配更大的内存空间,从而导致之前的地址失效。
map的迭代顺序都是随机的(取决于key的哈希算法),如果要显式按照key进行排序,可以使用
sort包。import "sort" var names []string for name := range ages { names = append(names, name) } sort.Strings(names) for _, name := range names { fmt.Printf("%s\t%d\n", name, ages[name]) }map上的大部分操作,包括查找、删除、len和range循环都可以安全工作在nil值的map上,它们的行为和一个空的map类似。但是向一个nil值的map存入元素将导致一个panic异常,所以在向map存数据前必须先创建map。
ages["carol"] = 21 // panic: assignment to entry in nil map和slice一样,map之间也不能进行相等比较;唯一合法操作是和nil进行比较。
4-4、结构体
一个命名为S的结构体类型将不能再包含S类型的成员:因为一个聚合的值不能包含它自身。(该限制同样适应于数组。)但是S类型的结构体可以包含*S指针类型的成员,这可以让我们创建递归的数据结构,比如链表和树结构等。
结构体类型的零值是每个成员都是零值。通常会将零值作为最合理的默认值。
如果结构体没有任何成员的话就是空结构体,写作struct{}。它的大小为0,也不包含任何信息,但是有时候依然是有价值的。但是因为节约的空间有限,而且语法比较复杂,所以不推荐这种用法。
seen := make(map[string]struct{}) // 类似于set,不推荐如果结构体的全部成员都是可以比较的,那么结构体也是可以比较的,那样的话两个结构体将可以使用==或!=运算符进行比较。相等比较运算符==将比较两个结构体的每个成员。
type Point struct{ X, Y int } p := Point{1, 2} q := Point{2, 1} fmt.Println(p.X == q.X && p.Y == q.Y) // "false" fmt.Println(p == q) // "false"匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针。
type Point struct{ X, Y int } type Circle struct { Point Radius int } // 或者 type Circle struct { *Point Radius int }
4-5、json、文本和HTML模板
结构体的成员Tag可以是任意的字符串面值,但是通常是一系列用空格分隔的key:”value”键值对序列。
type Movie struct { Title string Year int `json:"released"` Color bool `json:"color,omitempty"` Actors []string }Tag额外的omitempty选项,表示当Go语言结构体成员为空或零值时不生成JSON对象。
生成模板的输出需要两个处理步骤。
- 第一步是要分析模板并转为内部表示,
- 然后基于指定的输入执行模板。
分析模板部分一般只需要执行一次。
const templ = `xxxx` // 分析模板 var report = template.Must(template.New("issuelist").Funcs(template.FuncMap{"daysAgo": daysAgo}).Parse(templ)) // 执行模板 if err := report.Execute(os.Stdout, result); err != nil { log.Fatal(err) }
第5章:函数
在Go中,函数被看作第一类值(
first-class values):函数像其他值一样,拥有类型,可以被赋值给其他变量,传递给函数,从函数返回。对函数值(function value)的调用类似函数调用。函数类型的零值是nil。调用值为nil的函数值会引起panic错误:
var f func(int) int f(3) // 此处f的值为nil, 会引起panic错误函数值可以和nil作比较。但是函数值之间是不可比较的,所以不能用函数值作为map的key。
func square(n int) int { return n * n } f:=square f1:=square fmt.Println(f==f1)// invalid operation: f == f1 (func can only be compared to nil)要区分下go中的函数值和C语言的函数指针是有区别的,C语言的函数指针和变量的指针一样,它指向函数的起始位置。但是在GO中,函数值是一个引用类型,它不仅仅是一串代码,还记录了状态。所以把函数值称为闭包。这也是它不能进行比较的原因。
这里有一个迭代变量的坑,需要特别注意,问题的原因在于循环变量的作用域。
a:=[]int{1,2,3} var fun []func() for _,v:=range a{ fun=append(fun,func(){ fmt.Printf("v=%d\t",v) }) } for _,f:= range fun{ f() } // 输出结果:v=3 v=3 v=3 // 正确做法 for _,v:=range a{ vv := v fun=append(fun,func(){ fmt.Printf("v=%d\t",vv) }) }上面的例子中,为什么输出的都是
v=3,原因在与for循环的变量作用域和闭包共同作用的结果。- 第一:for循环语句引入了新的词法块,循环变量v在这个词法块中被声明(在进入for后),后面每次for代码体的执行都是更改这个变量v,而不是重新定义一个v。这一点要千万注意。
- 第二:闭包会引用到外部变量,所以,当v在每一次重新赋值后,它的改变也会反映到所有的闭包中。
闭包返回的包装对象是一个复合结构(所以它是一个引用类型),里面包含匿名函数的地址,以及环境变量的地址。这里变量分配在堆上。请参考这篇文章以及知乎上的问题:Golang中闭包的自由变量是如何进行存储的?。
虽然在可变参数函数内部,
...int型参数的行为看起来很像切片类型,但实际上,可变参数函数和以切片作为参数的函数是不同的。func f(...int) {} func g([]int) {} fmt.Printf("%T\n", f) // "func(...int)" fmt.Printf("%T\n", g) // "func([]int)"defer语句中的函数会在return语句更新返回值变量后再执行。
func double(x int) (result int) { defer func() { fmt.Printf("double(%d) = %d\n", x,result) }() return x + x } func triple(x int) (result int) { // 先将double(x)的结果赋值给result,然后调用defer函数,再将result的值加上x defer func() { fmt.Println("x=",x,"result=",result);result += x }() return double(x) } _=double(2) // 输出:double(2) = 4 fmt.Println(triple(4)) //输出: "12"在循环体中的defer语句需要特别注意,因为只有在函数执行完毕后,这些被延迟的函数才会执行。defer函数并没有在循环结束后调用。
通常来说,不应该对panic异常做任何处理,对于panic的recover,要遵循广泛的规范:
- 不应该试图去恢复其他包引起的panic
- 公有的API应该将函数的运行失败作为error返回,而不是panic
- 不应该恢复一个由他人开发的函数引起的panic,比如说调用者传入的回调函数
在recover时对panic value进行检查,如果发现panic value是特殊类型,就将这个panic作为errror处理,如果不是,则按照正常的panic进行处理。
type bailout struct{} defer func() { switch p := recover(); p { case nil: // no panic case bailout{}: // "expected" panic err = fmt.Errorf("multiple title elements") default: panic(p) // unexpected panic; carry on panicking } }() // 触发panic panic(bailout{})
第6章:方法
注意函数和方法的区别:在函数声明时,在其名字之前放上一个变量,即是一个方法。
在Go语言中,我们并不会像其它语言那样用this或者self作为接收器;建议是可以使用其类型的第一个字母,比如Point的首字母p。
一般会约定如果Point这个类有一个指针作为接收器的方法,那么所有Point的方法都必须有一个指针接收器,即使是那些并不需要这个指针接收器的函数。也就是说:如果结构体如果有一个方法需要指针作为接收器,那么其他的方法都要用指针作为接收器。
Nil也是一个合法的接收器类型,关于其中的原理,可以参考第四章slice部分的第三点笔记。
匿名字段其实可以看成一个语法糖,它是把类型名作为了结构体的字段名。
type Point struct{X,Y int} type ColorPoint struct { Point Color int } cp := ColorPoint{Point{1,2}, 100} // cp.X 等价于 cp.Point.X
6-1、关于函数和方法的个人理解
因为在go中,函数可以作为第一类值,所以,我猜想结构体的方法实现,大概类似于模具工厂生产成品的过程。首先,我们把一台磨具机器分成模具核心部件和其他附加部件两个部分。
- 模具部件就是一个结构体,它规定了生产出来的东西都是按照一定的规则形状(也就是结构体字段结构)
- 机器消耗的原料就是内存,机器冲压原料使其成型的过程就是创建一个结构体对象的过程
- 附加部件就是结构体的方法,它接收机器出来的成品进行加工打磨
所以,在go中,可以想象结构体是更加一层的封装(它就是一台完整的模具机器),它不仅仅包含了纯粹的结构体(模具部件)同时还有处理成品的其他方法(机器的附件部件)。这与C中的结构体有一点区别,C的结构体没有方法,所以C中的结构体就是一个模具部件,它冲压出来的成品,就需要人工拿去打磨加工,这个人工打磨加工的过程就需要其他方法来处理,因此这个加工方法跟结构体是独立分开的。
func (p *Point) ScaleBy(factor float64) { p.X *= factor p.Y *= factor }对于上面的例子,方法的名字是
(*Point).ScaleBy,我猜想它指向的就是一个函数地址。结构的方法调用可以看成是一个语法糖,例如上面的例子:p.ScaleBy(1.1) 等价于
(*Point).ScaleBy(p, 1.1),这跟很多脚本语言的语法糖类似,比如lua的语法糖:function Point:ScaleBy(factor),等价于function Point.ScaleBy(self, factor)。即第一个参数就是对象本身,关于是传入一个对象的值拷贝还是指针拷贝,就取决于方法的接收者类型。如果是指针,传入的p就是取地址后的一个指针,否则就是一个对象的值拷贝。下面的例子可以验证:
type Point struct{X,Y int} func (p *Point)Test(){ p.X=100 fmt.Println("Test",p.X,p.Y) } func main(){ p1 := Point{1,2} p2 := &Point{3,4} f := (*Point).Test fmt.Println(p1.Test, p2.Test, f) // 0x4988b0 0x4988b0 0x498450 p1.Test() // Test 100 2 p2.Test() // Test 100 4 f(p2) f(&p1) fmt.Printf("%T\t%T\n",p1.Test,f) // func() func(*main.Point) }通过上面的例子,可以证实结构体的方法底层就是一个函数,调用的时候讲结构体对象作为第一个参数传入。但是上面的例子中为什么
p1.Test和p2.Test地址是一样,但是和(*Point).Test为什么不一样?这里就要注意一点:p1.Test其实是个闭包才对,闭包里面调用的方法才是真正的(*Point).Test。因此有下面的关系:// 闭包 type C struct { F uintptr//这个就是闭包调用的函数指针,这里就是`(*Point).Test`的函数指针的地址 a *int //这就是闭包的上下文数据,也就是p1这个对象 } c:=C{(*Point).Test, &p1} p1.Test = c关于golang 闭包的底层实现,参考从汇编角度理解golang多值返回和闭包。
第7章:接口
接口类型是一种抽象的类型。它不会暴露出它所代表的对象的内部值的结构和这个对象支持的基础操作的集合;它们只会展示出它们自己的方法。也就是说当你有看到一个接口类型的值时,你不知道它是什么,唯一知道的就是可以通过它的方法来做什么。
interface{}被称为空接口类型,可以将任意一个值赋给空接口类型。接口值,由两个部分组成,一个具体的类型和那个类型的值。它们被称为接口的动态类型和动态值。类似于lua的底层设计。
在Go语言中,变量总是被一个定义明确的值初始化,即使接口类型也不例外。对于一个接口的零值就是它的类型和值的部分都是nil。以下三张图描述了接口值
w的变化。var w io.Writer w = os.Stdout w = new(bytes.Buffer)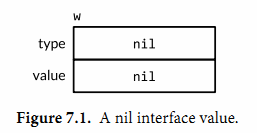
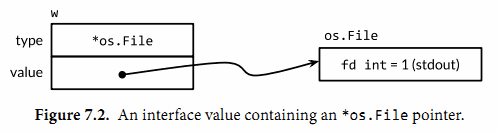
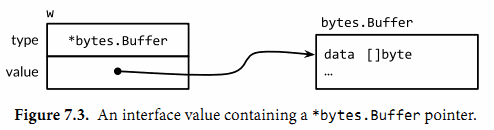
在编译期,我们不知道接口值的动态类型是什么,所以一个接口上的调用必须使用动态分配。因为不是直接进行调用,所以编译器必须把代码生成在类型描述符的方法Write上,然后间接调用那个地址。这个调用的接收者是一个接口动态值的拷贝,os.Stdout。
w.Write([]byte("hello")) // "hello" os.Stdout.Write([]byte("hello")) //等阶于上面接口值可以使用
==和!=来进行比较。两个接口值相等仅当它们都是nil值或者它们的动态类型相同并且动态值也根据这个动态类型的==操作相等。因为接口值是可比较的,所以它们可以用在map的键或者作为switch语句的操作数。但是,如果接口的类型值是不可比较的,例如slice,则比较会失败并panic。关于nil接口,可以查看golang笔记,这里不再赘述。
接口值的类型断言分为两种:
- 断言的类型T是一个具体类型
- 断言的类型T是一个接口类型
注意:对一个接口类型的类型断言改变了类型的表述方式,改变了可以获取的方法集合(通常更大),但是它保护了接口值内部的动态类型和值的部分。
类型断言有两种方式,一种是直接断言,一种是使用类型分支。
// 直接断言 if v,ok:=x.(TypeA);ok {/*...*/} // 类型分支,v表示就是转换后的具体类型的值 switch v:=x.(type) { case nil: // ... case int, uint: // ... case bool: // ... case string: // ... default: // ... }
第8章:Goroutines和Channels
两个相同类型的channel可以使用
==运算符比较。如果两个channel引用的是相同的对象,那么比较的结果为真。一个channel也可以和nil进行比较。channel的零值也是nil。Channel支持close操作,用于关闭channel,随后对基于该channel的任何发送操作都将导致panic异常。对一个已经被close过的channel进行接收操作依然可以接受到之前已经成功发送的数据;如果channel中已经没有数据的话将产生一个零值的数据。
换句话说:如果close了channel,是能读数据的,但是不能写入。就像一根水管,关闭了进水口,但是水管中剩余没有流完的水还是可以继续的。
基于无缓存Channels的发送和接收操作将导致两个goroutine做一次同步操作。因为这个原因,无缓存Channels有时候也被称为同步Channels。
不管一个channel是否被关闭,当它没有被引用时将会被Go语言的垃圾自动回收器回收。所以,close一个channel并不会导致channel被回收。
试图重复关闭一个channel将导致panic异常,试图关闭一个nil值的channel也将导致panic异常。
和垃圾变量不同,泄漏的goroutines并不会被自动回收,因此确保每个不再需要的goroutine能正常退出。
Go语言的range循环可直接在channels上面迭代。对channel的range等价于下面的代码。range操作依次从channel接收数据,当channel被关闭并且没有值可接收时跳出循环。
done:=make(chan int) for{ v,ok:=<-done if !ok{ break } } // range channel for v:=range done{ // TODO }关于如何关闭一个运行中的goroutine,严格上来说,除了退出进程,是没有其他操作可以关闭一个正在运行的goroutine,只能”自杀”,也就是goroutine自己执行完毕后退出。
一个没有任何case的select语句写作select{},会永远地等待下去。
第9章:基于共享变量的并发
Go的口头禅:“不要使用共享数据来通信;使用通信来共享数据”。
当我们能够没有办法自信地确认一个事件X是在另一个事件Y的前面或者后面发生的话,就说明x和y这两个事件是并发的。
一个函数在并发调用时没法工作的原因太多了,比如死锁(deadlock)、活锁(livelock)和饿死(resource starvation)。
数据竞争的定义:数据竞争会在两个以上的goroutine并发访问相同的变量且至少其中一个为写操作时发生。所以,可以从三个方面去避免数据竞争(根据自己的情况选择合适的方案):
- 第一:是不要去写变量,因为并发读是安全的
- 第二:避免从多个goroutine访问变量,将变量限定在了一个单独的goroutine中
- 第三:允许很多goroutine去访问变量,但是在同一个时刻最多只有一个goroutine在访问。这种方式被称为“互斥”。
对一个已经锁上的mutex来再次上锁,会导致程序死锁,程序没法继续执行下去。
所有并发的问题都可以用一致的、简单的既定的模式来规避。所以可能的话,将变量限定在goroutine内部;如果是多个goroutine都需要访问的变量,使用互斥条件来访问。
每一个OS线程都有一个固定大小的内存块(一般会是
2MB)来做栈,这个栈会用来存储当前正在被调用或挂起(指在调用其它函数时)的函数的内部变量。一个goroutine会以一个很小的栈开始其生命周期,一般只需要2KB,并且goroutine栈的大小会根据需要动态地伸缩(最大1GB)。操作系统线程是被内核所调度,所以从一个线程向另一个“移动”需要完整的上下文切换,也就是说,保存一个用户线程的状态到内存,恢复另一个线程的到寄存器,然后更新调度器的数据结构。这几步操作很慢,因为其局部性很差需要几次内存访问,并且会增加运行的cpu周期。
goroutine没有可以被程序员获取到的身份(id)的概念。也就是说,它不像线程都有一个唯一的id。
第10章:包和工具
默认的包名就是包导入路径名的最后一段,因此即使两个包的导入路径不同,它们依然可能有一个相同的包名。例如,
math/rand包和crypto/rand包的包名都是rand。三种比较特殊的包名:
- main包
_test后缀结尾的测试包(外部测试包)- 追加版本号信息的包,例如
gopkg.in/mgo.v2,使用时不需要带上v2,直接使用mgo.xxx
导入包时,可以加入前缀来给包定义别名:
_加下划线,表示匿名导入,表示只是引用该包,仅仅是为了调用init()函数,而不使用包中其他功能.加点号,表示省略调用,在调用时可以不用写包名- 加一个别名,例如:
import mongo gopkg.in/mgo.v2
Go语言的构建工具对包含
internal名字的路径段的包导入路径做了特殊处理。这种包叫internal包(内部),一个internal包只能被和internal目录有同一个父目录的包所导入。可以参考标准库的net包。go list -json packagename表示用JSON格式打印每个包的元信息。
第11章:测试
在
*_test.go文件中,有三种类型的函数:测试函数、基准测试(benchmark)函数、示例函数。- 测试函数是以Test为函数名前缀的函数,用于测试程序的一些逻辑行为是否正确
- 基准测试函数是以Benchmark为函数名前缀的函数,它们用于衡量一些函数的性能
- 示例函数是以Example为函数名前缀的函数,提供一个由编译器保证正确性的示例文档
测试失败的输出并不包括调用
t.Errorf时刻的堆栈调用信息,t.Errorf调用不会引起panic异常或停止测试的执行。如果需要停止测试,可以使用t.Fatal或t.Fatalf停止当前测试函数。测试大致可以分为4种:普通测试、随机测试、白盒测试、外部测试包
关于外部测试包:当我们进行包内测试时(即在包内的
_test.go文件中进行测试),可能会发生包的循环依赖,此时通过外部测试包的方式解决循环依赖的问题,也就是创建一个以_test结尾的测试包,打破包的循环依赖。另外,我们可以导出包内的内部函数,例如在包内创建一个
export_test.go文件,导出包内的内部函数,供外部测试包调用。// export_test.go package fmt var IsSpace = isSpace测试覆盖率命令:
go test -run=Coverage -coverprofile=c.out或者go tool cover -html=c.out。下面的命令运行基准测试。通过
-bench命令行标志参数手工指定要运行的基准测试函数。默认值是空,“.”模式将可以匹配所有基准测试函数。// -benchmem命令行标志参数将在报告中包含内存的分配数据统计 go test -bench=. -benchmem
第12章:反射
可以通过调用reflect.Value的CanAddr方法来判断其是否可以被取地址,例如:
x := 2 c := reflect.ValueOf(&x) d := c.Elem() fmt.Println(c.CanAddr()) // "false" fmt.Println(d.CanAddr()) // "true"通过指针间接地获取的
reflect.Value都是可取地址的,即使开始的是一个不可取地址的Value。在反射机制中,所有关于是否支持取地址的规则都是类似的。小心使用反射,原因有三:
- 基于反射的代码是比较脆弱的,反射是在真正运行到的时候才会抛出panic异常
- 反射的操作不能做静态类型检查,而且大量反射的代码通常难以理解
- 基于反射的代码通常比正常的代码运行速度慢一到两个数量级
第13章:底层编程
unsafe.Sizeof函数返回操作数在内存中的字节大小,参数可以是任意类型的表达式,但是它并不会对表达式进行求值。地址对齐因素,一个聚合类型(结构体或数组)的大小至少是所有字段或元素大小的总和,或者更大,因为可能存在内存空洞。
注意:内存空洞可能会存在一些随机数据,可能会对用unsafe包直接操作内存的处理产生影响
关于
unsafe包的三个比较常用的函数,参考笔记。下图例子描述了内存对齐的情况:var x struct { a bool b int16 c []int } //32位系统: Sizeof(x) = 16 Alignof(x) = 4 Sizeof(x.a) = 1 Alignof(x.a) = 1 Offsetof(x.a) = 0 Sizeof(x.b) = 2 Alignof(x.b) = 2 Offsetof(x.b) = 2 Sizeof(x.c) = 12 Alignof(x.c) = 4 Offsetof(x.c) = 4 //64位系统: Sizeof(x) = 32 Alignof(x) = 8 Sizeof(x.a) = 1 Alignof(x.a) = 1 Offsetof(x.a) = 0 Sizeof(x.b) = 2 Alignof(x.b) = 2 Offsetof(x.b) = 2 Sizeof(x.c) = 24 Alignof(x.c) = 8 Offsetof(x.c) = 8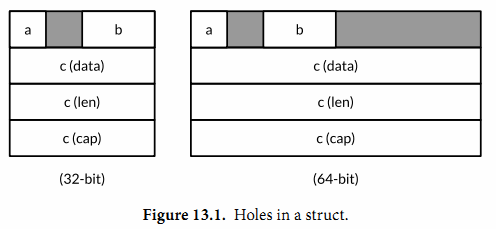
有时候垃圾回收器会移动一些变量以降低内存碎片等问题。这类垃圾回收器被称为移动GC。当一个变量被移动,所有的保存该变量旧地址的指针必须同时被更新为变量移动后的新地址。
从垃圾收集器的视角来看,一个
unsafe.Pointer是一个指向变量的指针,因此当变量被移动时对应的指针也必须被更新;但是uintptr类型的临时变量只是一个普通的数字,所以其值不应该被改变。所以下面的代码可能会有问题:
tmp := uintptr(unsafe.Pointer(&x)) + unsafe.Offsetof(x.b) pb := (*int16)(unsafe.Pointer(tmp))// 执行这行代码是,&x可能已经移到到新的内存,而tmp还是旧指针的地址 *pb = 42 // 正确的做法是在一个表达式内完成 pb := (*int16)(unsafe.Pointer(uintptr(unsafe.Pointer(&x)) + unsafe.Offsetof(x.b))) *pb = 42普通方法实现的函数尽量不要返回
uintptr类型,调用一个库函数,并且返回的是uintptr类型地址时,也要立即转换为unsafe.Pointer以确保指针指向的是相同的变量。要传入C函数的Go指针指向的数据本身不能包含指针或其他引用类型;并且C函数在返回后不能继续持有Go指针;并且在C函数返回之前,Go指针是被锁定的,不能导致对应指针数据被移动或栈的调整。具体可以阅读官方文档cgo。