CC BY 4.0 (除特别声明或转载文章外)
目录
- go编译
- package 别名
- go可见性规则
- 数组、切片(slice)、map
- defer、panic、recover
- import流程
- make 和 new的区别
- goroutine 和 channel
- const 和 iota
- 传参 和 传引用
- 接口 interface
- nil值
- 字符(byte、rune)、字符串(string)
- 类型定义与类型别名(type alias)
- 指针
- go tool pprof
- 学习资料
go编译
使用
go build编译go文件时,go文件必须放在最后,不然会有named files must be .go files的报错。例如:
go build -ldflags "-w" -o ./xlsx2lua.exe ./xlsx2lua.go减小golang编译的二进制文件大小:
go build -ldflags "-s -w",如果想进一步减小,可以使用upx对编译的二进制加壳压缩。s去掉符号表(然后panic时候的stack trace就没有任何文件名/行号信息了,这个等价于普通C/C++程序被strip的效果)w去掉DWARF调试信息,得到的程序就不能用gdb调试了。
golang发布闭源的.a文件(静态库),参考官方文档 Binary-Only Packages。
package 别名
import xxx “fmt” 表示xxx是系统包“fmt”的一个别名,在代码中可以使用 xxx.Println 来调用函数。
注意,当用一个点 “.”来作为一个包的别名时,表示省略调用,在调用时可以不用写包名,类似c++ 中 using namespace std,以后就不用写std::method这样的格式,但是不推荐。
go可见性规则
首字母大写表示public,小写表示private(注意:作用域是packge,即:在同一个包下,大小写都是可以访问的)。
数组、切片(slice)、map
数组和切片的区别和联系
数组:数组的容量和长度是一样的。cap() 函数和 len() 函数均输出数组的容量(即长度)。 切片:切片是长度可变、容量固定的相同的元素序列。Go语言的切片本质是一个数组。容量固定是因为数组的长度是固定的,切片的容量即隐藏数组的长度。长度可变指的是在数组长度的范围内可变。
golang map的key:只有function、map和slice三个kind不能作为map的key,struct能不能作为key,要看结构体中的字段是否存在前面所提到的三个类型,如果没有则可以作为key。
Go语言中的Array、Slice、Map和Set使用详解。
append函数返回值必须有变量接收,因为append操作可能会导致原来的slice底层内存发生改变。
golang map数据结构不能并发读写问题,最新版本的golang 1.9已经支持了并发安全的map(
sync.map)。
defer、panic、recover
这是golang中的异常处理函数。
defer函数(延迟函数):
当一个func执行完毕,就会执行defer语句,如果一个func中有多个defer,那么defer将按照逆序的顺序执行,通俗点说,就是哪个defer写在前面,那个defer就最后执行。这里有一个地方需要注意:defer应该是在return之前执行的,这里有一个网上的例子
func f() (result int) { defer func() { result++ }() return 0 }返回 result = 1,因为在函数f() return 之前,defer函数执行了一次。
func f() (result int) { return 0 defer func() { result++ }() return 0 }返回 result = 0,因为在defer之前,函数f() 就已经返回了。
panic:
是用来表示非常严重的不可恢复的错误的。在Go语言中这是一个内置函数,接收一个interface{}类型的值(也就是任何值了)作为参数。panic的作用就像我们平常接触的异常。不过Go可没有try…catch,所以,panic一般会导致程序挂掉(除非recover)。所以,Go语言中的异常,那真的是异常了。你可以试试,调用panic看看,程序立马挂掉,然后Go运行时会打印出调用栈。
但是,关键的一点是,即使函数执行的时候panic了,函数不往下走了,运行时并不是立刻向上传递panic,而是到defer那,等defer的东西都跑完了,panic再向上传递。所以这时候 defer 有点类似 try-catch-finally 中的 finally。 panic就是这么简单。抛出个真正意义上的异常。
recover:
上面说到,panic的函数并不会立刻返回,而是先defer,再返回。这时候(defer的时候),如果有办法将panic捕获到,并阻止panic传递,那就异常的处理机制就完善了。
Go语言提供了recover内置函数,前面提到,一旦panic,逻辑就会走到defer那,那我们就在defer那等着,调用recover函数将会捕获到当前的panic(如果有的话),被捕获到的panic就不会向上传递了,于是,世界恢复了和平。你可以干你想干的事情了。
不过要注意的是,recover之后,逻辑并不会恢复到panic那个点去,函数还是会在defer之后返回。
import流程
流程图: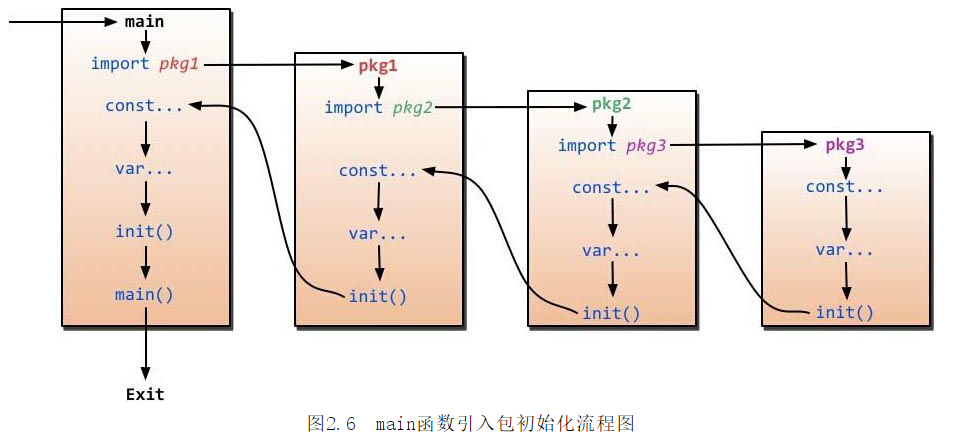
make 和 new的区别
转自: http://www.cnblogs.com/ghj1976/archive/2013/02/12/2910384.html
make用于内建类型(map、slice 和channel)的内存分配。new用于各种类型的内存分配。
new本质上说跟其它语言中的同名函数功能一样:new(T)分配了零值填充的T类型的内存空间,并且返回其地址,即一个
*T类型的值。用Go的术语说,它返回了一个指针,指向新分配的类型T的零值。有一点非常重要:new返回指针。make(T, args)与new(T)有着不同的功能,make只能创建slice、map和channel,并且返回一个有初始值(非零)的T类型(引用),而不是
*T。本质来讲,导致这三个内建类型有所不同的原因是:引用在使用前必须被初始化。例如,一个slice,是一个包含指向数据(内部array)的指针、长度和容量的三项描述符;在这些项目被初始化之前,slice为nil。对于slice、map和channel来说,make初始化了内部的数据结构,填充适当的值。make返回初始化后的(非零)值。
故make 是内建类型初始化的方法,例如:s :=make([]int,len,cap) //这个切片在元素在超过10个时,底层将会发生至少一次的内存移动动作
goroutine 和 channel
必须时刻警惕goroutine死锁的问题:
对于无缓冲的channel,它是同步阻塞的,非缓冲信道上如果发生了流入无流出,或者流出无流入,也就导致了死锁。或者这样理解 Go启动的所有goroutine里的非缓冲信道一定要一个线里存数据,一个线里取数据,要成对才行 。
对于有缓冲的channel,异步,缓冲信道不仅可以流通数据,还可以缓存数据。它是有容量的,存入一个数据的话 , 可以先放在信道里,不必阻塞当前线而等待该数据取走。当缓冲信道达到满的状态的时候,就会表现出阻塞了,因为这时再也不能承载更多的数据了,「你们必须把 数据拿走,才可以流入数据」。显示关闭chan需要调用close()方法,注意,当一个channel关闭后,是可以从里面继续读取数据的,只是无法写入。
所有的goroutine执行完毕的方式主要有两种:
- 使用
sync.WaitGroup - 使用
channel
- 使用
golang 中只要有一个goroutine发生panic整个进程都挂了。所以,golang中goroutine里面的panic应该在goroutine自己内部recover,别的goroutine是不能捕获到这个panic的。
const 和 iota
参考:Go语言iota与const、golang枚举类型 - iota用法拾遗
const:用来定义常量,和c++是一样的道理;
const 里面声明常量,有如下要求:- 其类型必须是:数值、字符串、布尔值;
- 表达式必须是在编译期可计算的;
- 声明常量的同时必须进行初始化,其值不可再次修改;
在const的定义列表中,如果某个变量没有右值,则该变量的右值等于上一个变量的右值;
const( A = 100 B // 此处B=100,使用了上一个变量A的右值 )
iota:用来定义枚举,iota 在 const结构里面使用, 记住一点,iota 是属于当前 const 里面的行数索引器(索引从0开始),不管中间有没有定义其他的变量;
- 只能在 const 里面使用;
- 是 const 里面的行数索引器;
- 每个 const 里面,iota 都从 0 开始;
- 在const里,每出现一次 iota,则自增1;
传参 和 传引用
关于这部分,主要参考两篇文章(都是干货):
golang: 常用数据类型底层结构分析
Go语言的传参和传引用
什么是引用类型?它和值类型有什么区别?
- 值类型: 直接存储变量的数据;
- 引用类型: 可以理解为指针,只不过把底层的指针封装了一下,采用了一些语法糖,隐藏了需要使用底层指针的语法;
关于这两者之间的区别,可以举个栗子:你钱包的钱可以直接拿来使用,就是值类型;而你存在银行的钱,它们托管在银行,就相当于引用类型,银行卡号就类似底层的指针。
什么是引用传递?它和值传递有什么区别?
- 值传递: 直接拷贝一份参数的值,然后传递给参数,记住它是一份拷贝,对它的改变是不会影响原本的参数;
- 引用传递: 类似传递了参数的一个别名,对它的改变会影响到原本的参数;
golang 中slice、map、chan都是引用类型,但是用它们做参数传递给函数,则是值传递(可以用 %p打印内存地址来对比),注意:不要混淆引用类型和引用传递;
golang 中slice特殊之处:map和chan做参数,对它们的修改,可以反映在原本的参数上,是因为底层的指针不会改变;但是如果对slice的参数进行append之后,底层的数组地址可能会发生改变。
注意区分slice的以下三种操作:
func main() { a := []int{1,2,3} fmt.Println(a) modifySliceData(a) fmt.Println(a) } // 这里只是修改了底层指针指向的值,所以原本的参数的值也发生了变化 func modifySliceData(data []int) { fmt.Printf("%p",&data) data[0] = 0 } // 这里append之后,底层的数组地址发生了变化 func appendSliceData(data []int) { fmt.Printf("%p",&data) data = append(data,4) // 注意:append并不会生成新的data,只会修改data底层指向数组的地址,以便存储append之后的值 } // 如果要操作原本的参数,应该传入slice的指针 func updateSliceData(data *[]int) { fmt.Printf("%p",data) *data = append(*data,4) // 此时,main函数的变量a=[]int{1,2,3,4} }
总结:
- 在golang中,函数传递参数都是值传递,闭包使用引用传递;
- 引用类型和传引用是不同的两个概念;
接口 interface
参考:http://www.jb51.net/article/56831.htm
当我们嵌入一个类型,这个类型的方法就变成了外部类型的方法,但是当它被调用时,方法的接受者是内部类型(嵌入类型),而非外部类型。—— Effective Go
接口的调用规则是建立在这些方法的接受者和接口如何被调用的基础上。下面的是语言规范里定义的规则,这些规则用来说明是否我们一个类型的值或者指针实现了该接口:
1.类型
*T的可调用方法集包含接受者为*T或T的所有方法集
这条规则说的是如果我们用来调用特定接口方法的接口变量是一个指针类型,那么方法的接受者可以是值类型也可以是指针类型。2.类型
T的可调用方法集包含接受者为T的所有方法,但不包含接受者为*T的方法
这条规则说的是如果我们用来调用特定接口方法的接口变量是一个值类型,那么方法的接受者必须也是值类型该方法才可以被调用。
在golang中,万物皆interface{},所以golang中可以将任意类型赋值给interface{},包括nil也可以赋值给interface{},interface{}有点像c艹中的纯虚基类,只包含了方法的集合。
interface在底层的实现包括两个成员:类型(_type)和值(data),我对 lua 比较熟,这点上类似 lua 的值在底层的实现,所以比较容易理解(我估计大部分动态语言都是这么干的吧)。 _type 表示存储变量的动态类型,也就是这个值真正是什么类型的。int?bool?…… data存储变量的真实值。
例如: var value interface{} = int32(100)
那么value在底层的结构就是:{_type:int32,data=100}
关于普通类型与interface{}的转换:
1、普通类型转换到interface{}是隐式转换;例如 fmt.Println(),我们可以传入任意类型的值,Println都会把传入的值转换成interface{}类型
2、interface{}转换成普通类型需要显式转换;
关于接口的实现:
假如有一个接口 type interface{} T, *T包含了定义在T和*T上的所有方法,而T只包含定义在T上的方法。
nil值
在golang中,nil只能赋值给指针、channel、func、interface、map或slice类型的变量。如果未遵循这个规则,则会引发panic。
如何判断一个interface{} 是否是 nil?
根据上面对interface{}的介绍,判断interface{}是否为nil的规则:
只有在内部值和类型都未设置时(nil, nil),一个接口的值才为 nil。特别是,一个 nil 接口将总是拥有一个 nil 类型。若我们在一个接口值中存储一个 int 类型的指针,则内部类型将为 int,无论该指针的值是什么:
(*int, nil)。 因此,这样的接口值会是非 nil 的,即使在该指针的内部为 nil。
那么思考如下问题:
type T struct{
Age int
Name string
}
func main(){
t1:= &T{20,"kaka"}
fmt.Printf("%p\n", t1)
fmt.Println(t1==nil)
//fmt.Println(*t1 == nil) //cannot convert nil to type test
}
为什么注释的那行会报错?我的分析是:
t1 真正指向的是 T类型的一个实例,是一个T类型的值,而nil值无法转换成除了指针、channel、func、interface、map或slice的类型,所以会报错。这也验证了: nil只能赋值给指针、channel、func、interface、map或slice类型的变量。如果未遵循这个规则,则会引发panic。
关于接口和nil主要参考:
- http://my.oschina.net/chai2010/blog/117923
- http://my.oschina.net/goal/blog/194233
- http://my.oschina.net/goal/blog/194308
字符(byte、rune)、字符串(string)
推荐使用
fmt.Printf("%+v\n", p),打印变量。golang的字符串,主要注意
rune类型和byte类型的区别。参考:学习Golang语言(4):类型–字符串。
类型定义与类型别名(type alias)
golang 1.9新增了一个新的特性:类型别名,它的语法如下:
type identifier = Type // identifier是Type类型的一个别名
类型别名和原类型完全一样,只不过是另一种叫法而已。所以,类型别名和类型定义最大的区别在于:类型别名和原类型是相同的,而类型定义和原类型是不同的两个类型。
使用类型别名需要注意一下几点,参考了解 Go 1.9 的类型别名:
- 防止出现类型循环
- 类型别名能改变原类型的可导出性
指针
指针转换
golang指针可以分为三种:
*类型,例如:*byte,表示一个byte指针,用于传递对象的指针,不能进行指针运算unsafe.Pointer,类似于C语言中的void*,表示通用类型指针(无类型指针),用于转换不同类型的指针,不能进行指针运算uintptr,指针的地址值,用于指针运算。
unsafe.Pointer 底层实际是一个*int,而uintptr底层是type uintptr uintptr,是一个无符号int值。
通俗的说:unsafe.Pointer是可以与普通类型指针进行转换,也可以和uintptr进行转换,即它是普通类型指针和uintptr之间的桥梁。可以让任意类型的指针实现相互转换,也可以将任意类型的指针转换为 uintptr 进行指针运算。
GC 不把 uintptr 当指针,也就是说 uintptr 无法持有对象,uintptr类型的目标会被回收,因为对于GC来说,uintptr就是一个无符号int值,上面也提到了uintptr的底层实现。
unsafe 包
参考官方文档Pointer。
三个函数:
func Alignof(x ArbitraryType) uintptr,返回变量对齐字节数量func Offsetof(x ArbitraryType) uintptr,返回变量指定属性的偏移量,这个函数虽然接收的是任何类型的变量,但是这个又一个前提,就是变量要是一个struct类型,且还不能直接将这个struct类型的变量当作参数,只能将这个struct类型变量的属性当作参数。func Sizeof(x ArbitraryType) uintptr,返回变量在内存中占用的字节数,切记,如果是slice,则不会返回这个slice在内存中的实际占用长度。
go tool pprof
关于go tool pprof性能分析工具的flat和cum(cumulative)的理解:
flat:函数自身执行所用的时间cum:执行函数自身和其调用的函数所用的时间和
以一个例子说明:设有这样的函数调用关系 a()-->b()-->(c()、d()),类似代码如下:
func a(){
b() // 调用b()
}
func b(){
c() // c()函数花费 1s
// do something //没有函数调用,但是执行发生了5s
// ...
d() // d函数花费 2s
}
b()函数的cum(累计调用时间)= 1+5+2 = 8s
b()函数的flat=5s,也就是b()函数自身执行自己代码的时间,没有发生函数调用