CC BY 4.0 (除特别声明或转载文章外)
本书一共21章。
第1章:UNIX基础知识
/etc/passwd文件为unix的口令文件,口令文件中的登陆项由7个以冒号分隔的字段组成,依次是:登录名、加密口令、数字用户id(UID)、组id(GID)、注释字段、起始目录以及使用的shell程序。其中,真实的用户密码存放在/etc/shadow中,组名存放在/etc/group中。domi:x:500:500::/home/domi:/bin/zsh git:x:502:502::/home/git:/bin/bashunix文件系统是目录和文件的一种层次结构,所有东西的起点是称为“根”(
root)的目录,这个目录的名称是一个字符“/”。文件描述符是一个小的非负整数,内核用来标示一个特定进程正在访问(例如:读文件、写文件、新建文件)的文件。
当运行一个新程序时,shell为其打开3个文件描述符,即标准输入(stdin)、标准输出(stdout)和标准错误(stderr)。可以重定向其中的一个或所有这3个描述符到某个文件。shell把文件描述符0与进程的标准输入关联,描述符1与进程的标注输出关联,描述符2与进程的标准错误关联。 ls > list.txt
一个进程内的所有线程共享同一地址空间、文件描述符、栈以及进程相关属性。
当unix系统函数出错时,通常会返回一个负值,而且整数变量errno通常被设置为具有特殊信息的值。
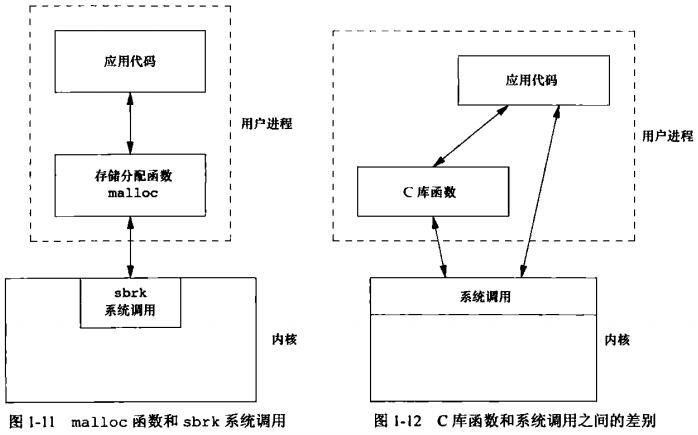
系统调用(system call)和C库函数调用的区别:
第2章:UNIX标准及实现
两个比较常见的标准,参考这篇文章
- ANSI C:这一标准是 ANSI(美国国家标准局)于 1989 年制定的 C 语言标准。 后来被 ISO(国际标准化组织)接受为标准,因此也称为 ISO C。它的目标是为各种操作系统上的 C 程序提供可移植性保证,而不仅仅限于 UNIX。
- POSIX:该标准最初由 IEEE 开发的标准族,部分已经被 ISO 接受为国际标准。POSIX.1 和 POSIX.2 分别定义了 POSIX 兼容操作系统的 C 语言系统接口 以及 shell 和工具标准。这两个标准是通常提到的标准。POSIX 表示可移植操作系统接口(Portable Operating System Interface ,缩写为 POSIX 是为了读音更 像 UNIX)。塔的目标是为了提高 UNIX 环境下应用程序的可移植性,而不仅仅局限于UNIX。
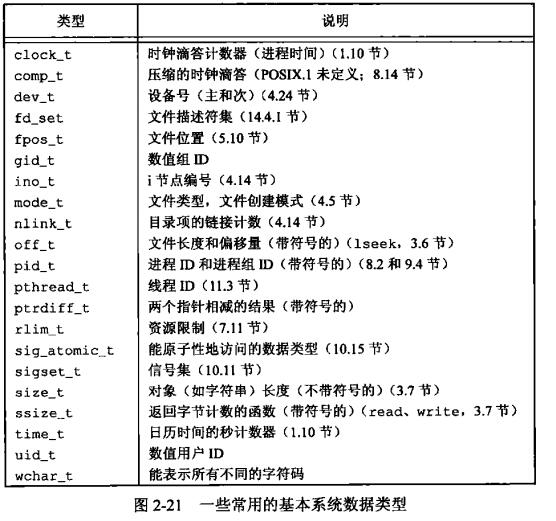
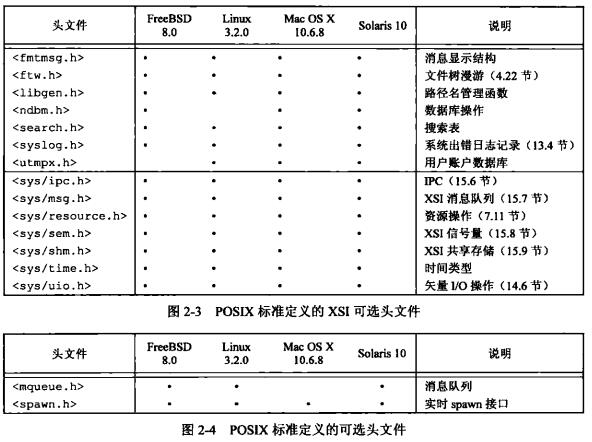
头文件<sys/types.h>定义了某些与实现相关的数据类型,它们被称为基本系统数据类型。下表列出了常用的基本系统数据类型。
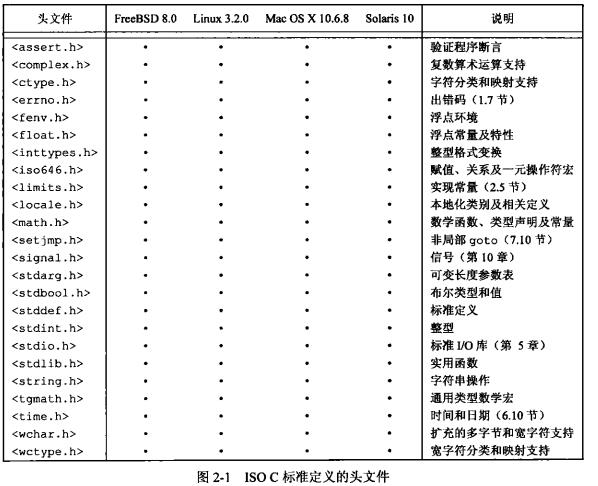
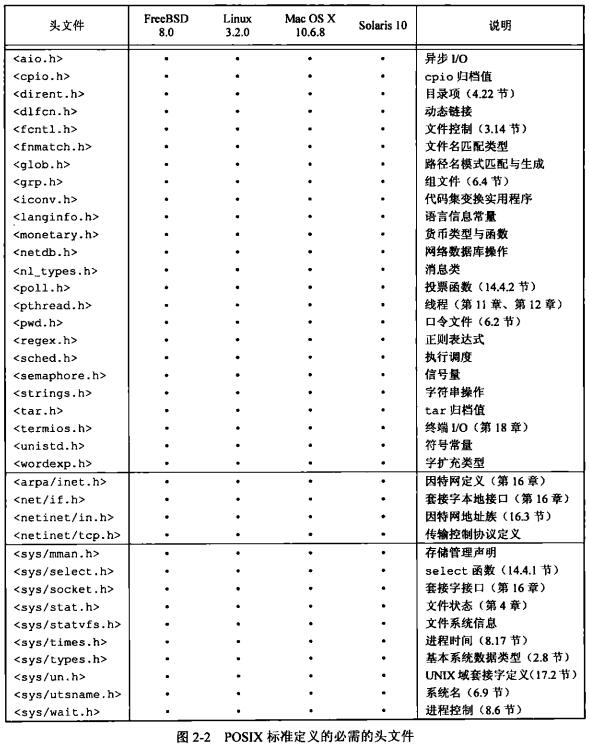
头文件列表
第3章:文件I/O
文件描述符标志只用于一个进程的一个描述符,而文件状态标志应用于指向该文件表项的任何进程中的描述符。
任何多于一个函数调用的操作都不是原子操作。因为在两个函数调用之间,内核可能会挂起进程。
原子操作指多步操作组成一个操作。执行原子操作,要么执行完所有操作,要么一个操作都不执行。
在
/dev/fd目录下,有名为0、1、2等的文件,打开文件/dev/fd/n等效于复制描述符(假定描述符n是打开的)。
第4章:文件和目录
unix文件类型
- 普通文件
- 目录文件
- 块特殊文件,这种类型的文件提供对设备(如磁盘)带缓冲的访问。
- 字符特殊文件,这种类型的文件提供对设备(如磁盘)不带缓冲的访问。
- FIFO,用于进程间通讯,命名管道。
- 套接字,用于进程间网络通讯。
- 符号链接,用于指向另一个文件,类似快捷方式。
文件的访问权限 : 每个文件有9个访问权限位,可以用
chmod命令来修改文件的访问权限位,权限位可以分为三组:- 用户读、用户写、用户执行,用
u (user)表示 - 组读、组写、组执行,用
g (group)表示 - 其他读、其他写、其他执行,用
o (other)表示
- 用户读、用户写、用户执行,用
关于文件权限:这篇文章有比较详细易懂的介绍。
第5章:标准IO库
当用标准IO库创建或者打开一个文件时,我们就使用了一个流与文件相关联了。
对一个进程预定义了3个流,并且这3个流可以自动被进程使用,它们是:标准输入、标准输出和标准错误,这些流所引用的文件与文件描述符
STDIN_FILENO,STDOUT_FILENO,STDERR_FILENO所引用的相同,这三个标准IO流通过预定义文件指针stdin,stdout,stderr加以引用,这三个文件指针定义在头文件<stdio.h>中。标准IO库提供的缓冲目的是为了尽可能减少使用
read和write调用的次数,标准IO库提供三种缓冲类型:- 全缓冲,在填满缓冲区后才进行实际的IO操作
- 行缓冲,在遇到换行符时,执行IO操作
- 不带缓冲,不对字符进行缓冲操作存储
第6章:系统数据文件和信息
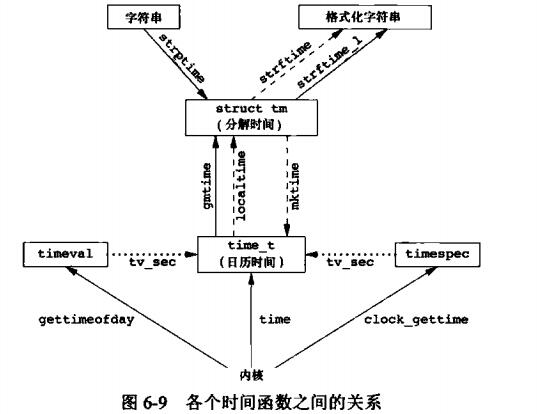
时间和日期例程:unix内核提供的基本时间服务是计算UTC(世界标准时间)公元1970年1月1日00:00:00这一特定时间以来的经历过的秒数。
#include<time.h> time_t time(time_t *calptr); // 返回unix时间戳两个函数
localtime和gmtime将日历时间(unix时间戳)转换成分解时间,并将结果存放在struct tm结构体中。localtime和gmtime的区别是:前者将日历时间转换成本地时间,而后者则转换成世界标准时间(UTC)的年、月、日、时、分、秒、周、日分解结构。
第7章:进程环境
C程序总是从main函数开始执行,main函数的原型如下:
int main(int argc, char *argv[]); // argc表示参数数量,argv表示参数进程的终止有8种方式,其实5种为正常终止:
正常终止:
- 从main返回
- 调用exit()或者_Exit(),
IOS C标准,头文件stdlib.h - 调用_exit,
POSIX.1标准,头文件unistd.h - 最后一个线程从其启动例程返回
- 从最后一个线程调用pthread_exit
异常终止:
- 调用abort()
- 接到一个信号
- 最后一个线程对取消请求做出响应
exit函数总是执行一个标准IO库的清理关闭操作:对于所有打开的流调用fclose函数。
main函数返回一个整型值与用该值调用exit是等价的,即:
return 0;等价于exit(0);,该整型值称为终止状态shell能够获取到进程的终止状态,例如:
echo $?。IOS C规定一个进程最多可以登记32个函数,这些函数将由exit自动调用,将这些函数称为终止处理程序,这些函数由atexit()来登记。#include <stdlib.h> int atexit(void (*func)(void));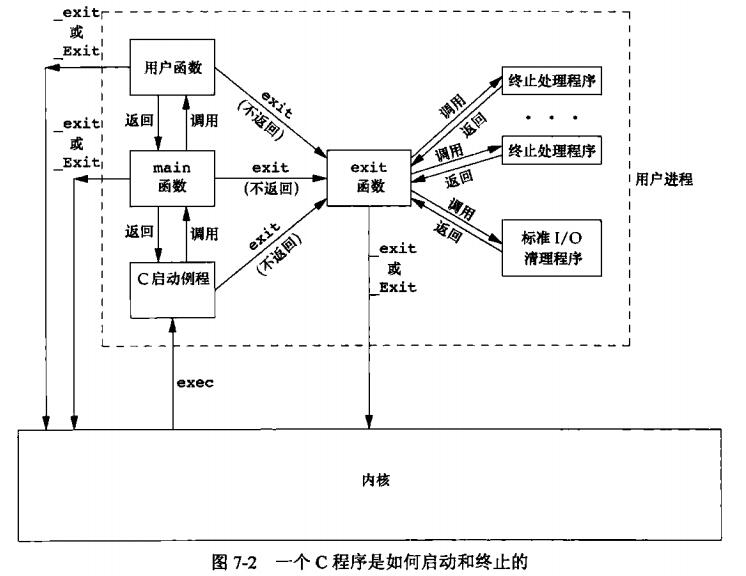
每个程序都接受一张环境表,历史上,大多数unix系统支持main函数带3个参数,第3个参数就是环境表地址:
int main(int argc, char *argv[], char *envp[]);但是,通常建议只用2个参数,推荐用getenv和putenv函数来访问特定的环境变量。
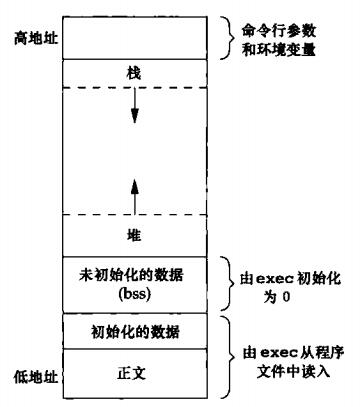
C程序的组成部分
- 正文段,这是由CPU执行的机器代码指令部分,可以共享(在存储器中只需要一个副本),并且是只读的
- 初始化数据段,包含了程序中已经明确赋初始值的变量,例如:
int maxcount=99; - 未初始化数据段,在程序开始执行之前(内核调用exec时),内核将此段的数据初始化为0或者空指针,例如:
long sum[100]; - 栈
- 堆,通常进行动态内存分配,位于未初始化数据段与栈之间
注意:栈向低地址增长;堆向高地址增长。所以,栈底是在高地址,栈是往下增长。
在C中,goto语句是不能跨函数使用的,而执行这类跳转功能的是函数
setjmp和longjmp。
第8章:进程控制
一般来说,在fork之后是父进程先执行还是子进程先执行是不确定的,这取决于内核所使用的调度算法。
fork的一个特性是父进程的所有打开的文件描述符都复制到了子进程中。
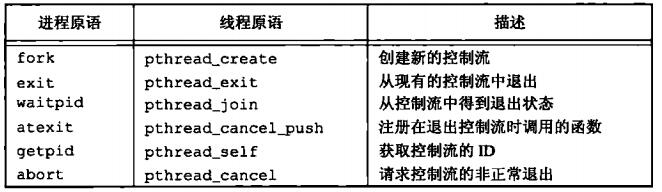
用fork可以创建新进程,用exec可以初始执行新的程序,exit和wait函数处理终止和等待终止,这些是我们需要的基本的进程控制原语。
七个exec函数之间的关系,只有
execve属于系统调用,其他6个则为库函数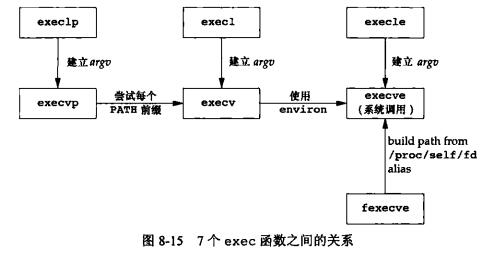
所有现今的unix系统都支持解释器文件(区别于编译器文件),这种文件是文本文件,文件的起始形式:
#! pathname [optional-argument], 当内核调用exec所执行的进程实际执行的并不是该解释器文件,而是解释器文件第一行中的pathname。举例:参考这里,下面区分一下在shell命令行上,执行一个shell脚本的不同方式,假设脚本名字为test.sh,脚本位于当前目录:
(1)输入命令行:sh test.sh,这种方式是在shell中执行/bin/sh程序,然后将test.sh脚本文件作为其参数执行,/bin/sh程序会查找当前目录找到test.sh;
(2)输入命令行:./test.sh,这种方式就是上面所说的解释器文件的执行过程,shell首先会将test.sh文件当做二进制机器文件,之后会由解释器(根据第一行判断,例如可以是/bin/sh)解释执行。当然,这种方式要求test.sh必须是一个可执行文件,上述(1)可以不是。
(3)输入命令行:test.sh,这种方式和上述(2)类似,区别是(2)告诉shell在当前目录查找该文件,而该方式下,test.sh的路径必须在系统的环境变量中(即PATH变量),否则系统找不到该可执行程序文件,值得注意的是PATH变量是没有包含当前目录的。
第9章:进程关系
第10章:信号
在某个信号出现时,可以告诉内核按以下三种方式进行处理,称之为信号的处理。
- 忽略此信号,大多数信号可以使用这种处理方式,但是有两种信号决不能被忽略,它们是
SIGKILL和SIGSTOP - 捕捉信号,注意,不能捕捉
SIGKILL和SIGSTOP信号 - 执行系统默认动作,注意,大多数信号的默认动作是终止进程
注意:不能忽略和捕捉
SIGKILL和SIGSTOP信号,也就是说,在你的代码里面,不要去处理这两个信号。- 忽略此信号,大多数信号可以使用这种处理方式,但是有两种信号决不能被忽略,它们是
当一个信号产生时,内核通常在进程表中以某种形式设置一个标示,当对某个信号采取这种动作时,我们说向进程传递了一个信号。在信号产生(generation)和信号传送(delivery)之间的时间间隔内,称信号是未决的(pending)。
POSIX.1允许系统传送信号一次或多次,如果传送信号多次,则称这些信号进行了排队,但是除非支持POSIX.1实时扩展,否则大多数UNIX系统并不对信号排队,而是只传递信号一次。
第11章:线程(重点)
一个进程的所有信息对该进程的所有线程都是共享的,包括可执行程序的代码、程序的全局内存和堆内存、栈以及文件描述数。
linux2.4和linux2.6在线程上的实现是不同的,前者是用一个单独的进程来实现每个线程,这使得它很难和POSIX线程的行为匹配,而linux2.6采用Native POSIX线程库的新线程实现。
如果进程中的任意线程调用了 exit、_exit或者_Exit,那么整个进程就会终止。单个线程可以通过3种方式退出:
- 线程可以简单的从启动例程中返回,返回值是线程的退出码
- 线程可以被同一个进程中的其他线程取消
- 线程调用pthread_exit
进程原语和线程原语
线程同步
互斥(mutex)量:从本质上来说就是一把锁,在访问共享资源时对互斥量进行设置(加锁),在访问完后释放(解锁)互斥量。
互斥量相关的5个函数:
- pthread_mutex_init ,初始化互斥量
- pthread_mutex_destroy,销毁互斥量
- pthread_mutex_lock,对互斥量加锁,如果互斥量已经上锁,调用线程则阻塞直到互斥量被解锁
- pthread_mutex_trylock,尝试对互斥量加锁,如果互斥量已经上锁,该函数会失败,并返回EBUSY,它不会阻塞线程
- pthread_mutex_unlock,对互斥量解锁
- pthread_mutex_timelock,对互斥量加锁,如果互斥量已经上锁,并且线程阻塞时间超时,则返回错误码ETIMEOUT
死锁:
- 如果线程对同一个互斥量加锁两次,就会陷入死锁。
- 当线程使用一个以上的互斥量时,如果线程A一直占有一个互斥量MA,并试图锁住第二个互斥量MB时处于阻塞状态,但是拥有第二个互斥量MB的线程B也在试图锁住互斥量MA,因此,两个线程都在相互请求另一个线程所拥有的资源,两个线程都无法向前运行,于是产生死锁。
对于第二种死锁情况,可以想象这样一个电影常见的场景:两伙黑帮交易,双方都互相不信任,一方想先拿到钱,再给货,另一方想先验货,再付钱,于是就这样焦灼着,这就是两个黑帮的死锁。
读写锁(reader-writer lock):与互斥量类似,不过读写锁允许更高的并行性。
- 互斥锁只有两个状态:加锁、不加锁,并且一次只有一个线程可以对其加锁。读写锁有三种状态:读模式下加锁、写模式下加锁、不加锁。一次只有一个线程可以占有写模式下的锁,但是可以多个线程同时占有读模式下的锁。
- 读写锁的相关函数与互斥量类似,例如:
pthread_rwlock_rdlock、pthread_rwlock_wdlock
条件变量:条件变量给多个线程提供了一个会合的场所,条件变量和互斥量一起使用时,允许线程以无竞争的方式等待特定的条件发生。 条件自身是由互斥量保护,也就是说,线程在改变条件状态前必须先锁住互斥量,同理,互斥量必须锁住后才能计算条件。
条件变量的相关函数:
- pthread_cond_init,初始化一个条件变量
- pthread_cond_destroy,销毁
- pthread_cond_wait、pthread_cond_timewait,等待条件变为真
- pthread_cond_signal,唤醒一个以上等待该条件的线程
- pthread_cond_broadcast,唤醒所有等待该条件的线程
自旋锁:与互斥量类似,但是它不是通过休眠是进程阻塞,而是在获取锁之前一直忙等(自旋),它适用于:锁被持有的时间短,且线程并不希望在重新调度上花费太多成本。
自旋锁和互斥量的区别:Mutex属于
sleep-waiting类型的锁。例如在一个双核的机器上有两个线程(线程A和线程B),它们分别运行在Core0和 Core1上。假设线程A想要通过pthread_mutex_lock操作去得到一个临界区的锁,而此时这个锁正被线程B所持有,那么线程A就会被阻塞 (blocking),Core0 会在此时进行上下文切换(Context Switch)将线程A置于等待队列中,此时Core0就可以运行其他的任务(例如另一个线程C)而不必进行忙等待。而Spin lock则不然,它属于busy-waiting类型的锁,如果线程A是使用pthread_spin_lock操作去请求锁,那么线程A就会一直在 Core0上进行忙等待并不停的进行锁请求,直到得到这个锁为止。所以,自旋锁一般用用多核的服务器。屏障:是用户协调多个线程并行工作的同步机制,它允许每个线程等待,直到所有的合作线程都达到某一点,然后从该点继续执行。
pthread_join就是一种屏障,它允许一个线程等待,直到另一个线程退出。
第12章:线程控制
如果一个函数在相同的时间点可以被多个线程安全的调用,则称改函数是线程安全的。
支持线程安全函数的操作系统实现会在
中定义符号`_POSIX_THREAD_SAFE_FUNCTIONS` 非线程安全函数以及可以替代的线程安全函数

如果一个函数对于多个线程来说是可重入的,就说这个函数是线程安全的,但是这并不说明对信号处理程序来说,该函数也是可重入的,如果函数对于异步信号处理程序的重入是安全的,那么就说该函数是异步信号安全的。
一个进程中的所有线程都可以访问进程中的整个地址空间。除了使用寄存器以为,一个线程没有办法阻止另一个线程访问它的数据。
pthread_cancel调用并不会等待线程终止,在默认情况下,线程在取消请求发起后还是继续运行,知道线程达到某个取消点。取消点是线程检查它是否被取消的一个位置。
第13章:守护进程
ps命令可以打印系统中各个进程的状态,例如:ps -axj,在ps的输出实例中,内核守护进程的名字出现在方括号中。在linux中,kthreadd为其他内核进程的父进程。
大多数守护进程都是以超级用户(root)特权运行,所有的守护进程都没有控制终端,其终端名设置为问号,内核守护进程以无控制终端的方式启动。
大多数用户层守护进程都是进程组的组长进程以及会话的首进程,而且是这些进程组和会话的唯一进程。
用户层的守护进程的父进程是 init进程。
守护进程与后台进程的区别:
- 后台进程的文件描述符也是继承于父进程,例如shell,所以它也可以在当前终端下显示输出数据。
- 守护进程自己变成了进程组长,其文件描述符号和控制终端没有关联,是控制台无关的。
- 基本上任何一个程序都可以后台运行,但守护进程是具有特殊要求的程序,比如要脱离自己的父进程,成为自己的会话组长等,这些要在代码中显式地写出来。换句话说,守护进程肯定是后台进程,但反之不成立。
守护进程可以通过
syslog来处理出错信息。记录和文件锁机制为创建单例守护进程提供了基础。
第14章:高级I/O
第15章:进程间通信
管道,它有两个局限性:
- 它是半双工的(现在某些提供全双工管道)
- 它只能在具有公共祖先的两个进程之间使用
单进程中使用管道没有任何意义。
当管道的一端被关闭后,有两条规则:
- 当读一个写端关闭的管道时,当所有数据都读完后,read返回0,表示文件结束
- 当写一个读端关闭的管道时,则产生信号
SIGPIPE。write返回-1,errno设置EPIPE